


1. Introduction
A disaster situation can come from anywhere, whether it is a storm that floods headquarters, a pandemic that forces staff to work remotely, or a cyberattack which leaves systems compromised, it is important in situations like these to have plans ready to ensure your staff and business can keep running. Even if not at full capacity, it is vital for the survival of your business to reach a position where you can serve your customers with an acceptable level of service experience as quickly as possible. The act of developing strategies to mitigate the risks from unexpected events is at the core of business continuity management and a vital process that all businesses should undertake. Unfortunately, research shows that as few as 35% of smaller companies have adequate recovery plans in place and only 10% of those which have no recovery process at all will survive a major incident. A system Disaster Recovery Plan (DRP) is a subset of the overall business continuity plan, and the process of system recovery is the topic that we will focus on here. The DR plan is a documented approach with instructions on how to respond to unplanned incidents which involves restoring vital support systems including server facilities, IT assets, and other critical infrastructure systems and data. The purpose of a disaster recovery plan is to minimise business and service downtime and restore technical operations back to normal running within the shortest possible time span. Like many areas of business strategy and planning, trade-offs are required when creating a DR plan which will involve an assessment of risk versus the costs of downtime for key elements of your business operations.

What are your costs of downtime?
The downtime of critical IT systems will impact the normal flow of business processes in some way and in nearly every case result in lost revenue. The exact cost of downtime is of course a very difficult quantity to measure. Many factors come into play such as the size of your business, industry sector, the actual duration of the outage, the number of people impacted and the time of day. Typically, losses are significantly higher per hour for businesses who are based on high-level data transactions such as banks and online retail stores. There have been many high-profile examples including the 14-hour outage in 2019 which cost Facebook an estimated $90 million and in 20161, a five-hour power outage in a Delta Airlines operation center caused 2,000 cancelled flights and an estimated loss of $150 million2. Of course, these are industry leaders with huge operating margins and millions in the bank, they can ride out a one-day financial storm far better than most. Smaller companies may face smaller losses during a major incident; however, the overall impact can be far more damaging even to the point of bankruptcy. Industry analyst firm Gartner conducted a cost of downtime survey in 2014 which determined the average cost of IT downtime to be $5,600 per minute. The report showed that due to the wide differences in how businesses operate, downtime, at the low end, can be as much as $140,000 per hour, $300,000 per hour on average, and as much as $540,000 per hour at the higher end3. Of course, fast forward to 2022 and these figures will undoubtedly be much higher. An elementary way to determine the cost of downtime for sections of your business is to determine how many employees have been affected, calculate their average hourly salary, then decide the impact of downtime on their productivity. For example, if your entire production line goes down, the impact on your manufacturing department would be 100%, then apply the formula: Cost of downtime = (number of affected employees) x (impact on productivity) x (average hourly salary)In addition, there are several less-tangible costs of downtime such as the impact on employee moral, your reputation, brand and customer loyalty that must be considered. Beyond the value to DR planning and building operational resilience, cost of downtime analysis can help you think strategically about your business model and allows you to better understand your business from a tactical standpoint.

What are acceptable RTOs & RPOs for your business functions?
For each business function it is important to determine acceptable Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO). In certain cases, these parameters will be driven by specific Service Level Agreements that you may have with customers or even within the organisation. As the names suggest, RTO defines the maximum acceptable time that it should take to completely recover a system to its function state prior to the outage scenario. RPO is defined as the maximum amount of data, as measured by time, that can be lost after a recovery from a disaster or comparable event before data loss will exceed what is acceptable to the organization. It is important that these parameters are calculated assuming a worst-case scenario. Very often RTO calculations are based on estimations for a manual single system recovery without considerations for the underlying infrastructure. In many situations such as a cyberattack or natural disaster, the reality will be that multiple systems require recovery which will significantly increase the true RTO and reinforce the fact that manual recovery of systems is impractical. Multiple system recovery should be factored in order establish a true estimation of RTO with recovery automation playing a vital role in the restoration process. To shorten the RTO or narrow the RPO generally involves increased costs, hence the need to conduct a risk assessment and a cost of downtime calculation for each system you wish to protect before setting these parameters.
2. Risk Identifaction
Performing a risk assessment
Before implementing a DRP, an assessment of risks and all the potential vulnerabilities your business may be prone to should be performed. DR risk assessment determines potential risks to the functioning of an organization resulting from both natural and man-made disasters, with a probability estimate of each scenario occurring. The results of these estimations should then be multiplied by the cost of downtime for each scenario. The value determined defines the level of protection your organization should consider against a given threat. However, in certain cases there may be longer term penalties to consider, especially where data loss could mean contravening industry compliance regulations. For example, if you are a health sector organization governed by HIPPA regulations for protecting electronic protected health information (ePHI) that specifically require a secure backup of “retrievable exact copies of electronic protected health information” and a flood wipes out all your data, the compliance issues from destroyed records will linger for months or even years afterward if you did not have a safe backup site. Whether the disaster is natural or man-made, it is also important to identify and plan for situations where you may not have access to the resources and staff you are accustomed to during normal business operations in addition to any loss of systems.

Risk types and characteristics
Natural Disaster
A natural disaster will often affect access to buildings and supporting infrastructure, therefore complete site replication should be considered if your risk assessment indicates such an event to have sufficient probability. Replication site location will need consideration if you are in an area prone to natural events. For instance, consider a finance firm located in San Francisco, CA. Finance is a strictly regulated industry, and firms are required to maintain records in a very specific manner. Also, since the firm is in CA, there is an elevated risk for earthquakes. Given these constraints, they should ensure that data centers are backed up to avoid fines if a data center is destroyed, and that replication sites are in other locations that as less susceptible to earthquakes. Likewise, if you are located within a flood plain, local on-site replication is probably not your safest option.
Human Error
The most common form of human error is accidental file or folder deletion. To mitigate these situations regular backups of important data volumes should be scheduled so that deleted items can be restored from an appropriate point-in-time copy. Of course, humans can go far beyond accidental file deletion and perform unwanted tasks such as accidental system shutdown, network cable disconnection, incorrect data entry and unfortunately, they are your highest risk when it comes to facilitating cybercrime. 98% of cyberattacks rely on social engineering5 to either gain login and personal details, or to deliver a malware payload through staff opening malicious file attachments. Aside from the cyber risks humans present, which are a topic worthy of far more discussion than can be covered here, errors such as accidental shutdowns and file deletions can be reduced by limiting system physical access to necessary staff, and likewise limiting login access to only essential staff for your most critical systems.
Power outage
Unplanned power outages will result in non-graceful shutdown of systems which may result in lost transactions or corrupted data files. At a minimum, critical systems should be supported with an Uninterruptible Power Source (UPS) which provides emergency power when the input power source or mains power fails. The UPS will be able to provide power for a finite amount of time to facilitate a graceful shutdown, or to allow alternative power from backup generators to be applied if available. Replication to the cloud or a separate physical site can provide fail-over in the event of a power failure, however network access and communication systems may also be affected by the power outage so alternative network access methods should be factored into the DRP.
Hardware Failure
System failure due to underlying hardware can be progressive, or instant and catastrophic. Hard disk drives (HDDs) due to their moving mechanical parts very often exhibit a progressive failure pattern which can be mitigated by implementing data protection mechanisms such as the various levels of RAID available. Similarly, although they do not have moving parts, flash-based storage and SSD drives have a finite lifespan, plus wear characteristics which limit their usable capacity over time. SSDs are relatively new to the market; hence manufacturers are still trying to determine their lifespan. Current estimates place a 10-year age limit for SSDs although the average SSD lifespan in practice appears to be shorter. Researchers undertaking a joint study between Google and the University of Toronto tested SSDs over a multi-year period and found SSDs were replaced approximately 25% less often than HDDs4. Likewise, system memory can exhibit progressive failure, however due the fact that system memory is typically holding application code instructions and operating data, most memory failures will result in an application or operating system crash. System board level failures are typically catastrophic resulting in the need to replace the effected board or recover a complete system image onto a replacement physical machine. Unless the replacement machine hardware is identical to the original, the recovery process may encounter problems due to differences in boot critical drivers resulting in lengthy intervention from IT support teams. A solution for seamlessly recovering systems to dissimilar hardware is outlined in section 3.
Upgrade error
Human ErrorThe most common form of human error is accidental file or folder deletion. To mitigate these situations regular backups of important data volumes should be scheduled so that deleted items can be restored from an appropriate point-in-time copy. Of course, humans can go far beyond accidental file deletion and perform unwanted tasks such as accidental system shutdown, network cable disconnection, incorrect data entry and unfortunately, they are your highest risk when it comes to facilitating cybercrime. 98% of cyberattacks rely on social engineering5 to either gain login and personal details, or to deliver a malware payload through staff opening malicious file attachments. Aside from the cyber risks humans present, which are a topic worthy of far more discussion than can be covered here, errors such as accidental shutdowns and file deletions can be reduced by limiting system physical access to necessary staff, and likewise limiting login access to only essential staff for your most critical systems.Upgrade errorMost elements within an IT infrastructure require regular software or firmware updates to provide bug fixes, new features and most importantly the closure of any cyberattack vulnerabilities which may have been discovered by equipment manufacturers. Therefore, regular updates are generally a good thing and highly recommended in the fight against cybercrime. Upgrades may cause problems where compatibility between applications is affected. This may need to be remedied by upgrading associated applications in the correct sequence, or in some cases a roll back to an earlier version may be the only option to maintain application-to-application compatibility. Most patch upgrades will have a roll back or uninstall capability. If this is not the case, restoration to an earlier version from a point-in-time backup may be the only option. Likewise, it is not unknown for patch files to contain bugs causing an upgrade to fail necessitating a roll back. Many software applications, operating systems and network devices offer automated updates which can present unexpected upgrade problems and unscheduled downtime, therefore patch management is an important task which requires specific planning and focus to avoid unwanted downtime.
Legacy System Support
Although the transition of many business applications to the cloud and the as-a-service model of platform delivery are becoming increasingly widespread, there are many enterprises that reply on sector specific legacy applications that do not have a cloud migration plan in the short term. Certain legacy applications will in turn require the prolonged use of a legacy operating system which may have passed ‘end of support’ which means the developer of the operating system will no longer provide technical support, and more importantly, will no longer provide updates to the operating system. This can present a security vulnerability that may require specific attention to ensure vital data is protected and/or that certain systems are ring fenced from the main network. Legacy applications can present additional challenges in DR scenario as a system rebuild may be reliant on the availability of the original application media such as installation CD/DVDs, plus any subsequent patch files required to take the application to its most current version. The same will apply to the underlying legacy operating system. For these reasons the use of system recovery software and/or system replication can be vitally important to ensure the recovery of legacy systems following a disaster. Cristie Software simplifies the protection of legacy applications through our extensive support matrix for legacy operation systems including many that are currently in end of support status. Modern backup software tools are usually released providing support for the most current OS versions with support for older versions added later, driven by customer demand, so it is important to check the OS compatibility matrices for all data protect tools you plan to use where legacy applications are involved.
Computer Virus
Computer viruses are almost always invisible. Without antivirus software installed on your systems and end point devices, you may not know you have one. The damage caused by viruses can vary, however the least damaging can usually be deleted or quarantined using your chosen antivirus software. The process typically follows the sequence of steps below.
- Disconnect the system from all networks
- Reboot the system into ‘Safe mode’ per OS instructions
- Delete any temporary files
- Run a virus scan
- Delete or quarantine any detected files(s)
- Rescan the system to check for any further threats
- Reboot the system into normal operating conditions
- Change all passwords
- Ensure all OS, applications, browsers, and network elements have the latest software updates
- Reconnect the system to the network
A key point to understand is that traditional malware protection systems, including firewalls and antivirus software, use a protection technique known as blacklisting. This approach is based on maintaining a list of protective signatures for malware codes that should be denied access to the network.This is an effective technique but a time consuming one; both for the security software companies that constantly must maintain definition files to detect and isolate all known malware codes, and for the IT staff who must ensure that all system patches and definition files are kept up to date. Malware and virus payloads are designed to exploit vulnerabilities that have been found within the technology stack, these could be within an operating system, the network infrastructure, an application, or anything in between. Herein lies the key failing of the blacklisting approach; you are constantly patching security holes that are already known and being exploited; hence the reason IT security teams are always on the back foot against cybercrime.The traditional blacklisting approach is a reactive one which allows new and unknown malware codes to infiltrate and propagate undetected before they wreak their havoc. These new vulnerabilities are known as ‘zero day’ exploits. Until these vulnerabilities are mitigated, hackers can continue to exploit them to adversely affect system applications, company data and additional computers on the network.
Cyberattack
A cyberattack is an orchestrated attack on a company’s network, systems, infrastructure, and data which has manual intervention from an individual or team of hackers. The attacker’s goals are usually to paralyze vital business systems by locking and/or encrypting the systems and data they require to operate. A ransom demand is then issued on the premise that a decryption key will be provided upon payment. A more recent attack trend is the additional exfiltration of confidential company information and Personally Identifiable Information (PII) on the threat of leaking this information publicly, or for sale via the dark web. Very often a cyberattack is initiated through the delivery of a computer virus (malware code) as described previously. The virus is typically delivered via a phishing email which dupes the recipient into downloading an attachment containing the malware code into their computer or device. The malware code then establishes a backdoor into the IT network and reports back to the hackers that a path of entry has been created. Alternatively, hackers will look to exploit previously unknown (zero-day) vulnerabilities within elements of a corporate network, such and switches and routers, computer operating systems, or in fact any network attached device that may provide an undetected gateway.
Communications outage
Some companies still reply on a PBX (Private Branch Exchange) while many have opted for internet-based VoIP (voice over internet protocol), or a cloud based unified communications as-a-service platform (UCaaS). Clearly power and network outages can impact communications systems, however, it is not uncommon for a cyberattack to render a company’s communications infrastructure inoperable. Companies who have left the traditional PBX behind and made the move to a cloud-based PBX are in a far better position in terms of communications availability due to the build-in redundancy these systems offer. None the less, it is important for companies to have alternative communications platforms at the ready to at least communicate internally in the event of a disaster. There are numerous options to consider many of which are extremely popular within everyday business communications such as Microsoft Teams, Skype, Zoom and even social platforms such as WhatsApp and Meta Platforms Messenger (formerly Facebook). At a minimum, alternative contact details for key staff should be documented within the chain of command section of your DRP.
“In February 2021, the state of Texas suffered a major power crisis as a result of three severe winter storms sweeping across the United States.Damages due to these storms were estimated to be at least $195Bn, likely the most expensive disaster in the state’s history6. “
3. Creating a DR Plan Document
What is a DR plan?
A disaster recovery plan documents the procedures and resources that an organization uses to recover from a major disruption to its IT infrastructure. Disaster recovery planning can use a variety of tools depending on the organization’s existing assets and recovery goals. DR plans will typically include the following parameters:
- Audit of critical systems and applications
- Recovery Point Objectives (RPO) for each business process.
- Recovery Time Objectives (RTO) for each business process.
- Location of data backups and replication site. Creating a secondary offsite backup or replica of your most important systems and data is a core part of any disaster recovery solution.
- Chain of command / accountability chart. A list of who is responsible for enacting the disaster recovery plan. Having assigned roles and responsibilities will make it easier to follow and enforce a plan quickly and consistently.
- DR testing plan. DR plans require frequent testing to ensure recovery procedures work and to ensure that RTOs, RPOs and SLAs can be met in a real emergency.
Typical steps in DR plan preparation
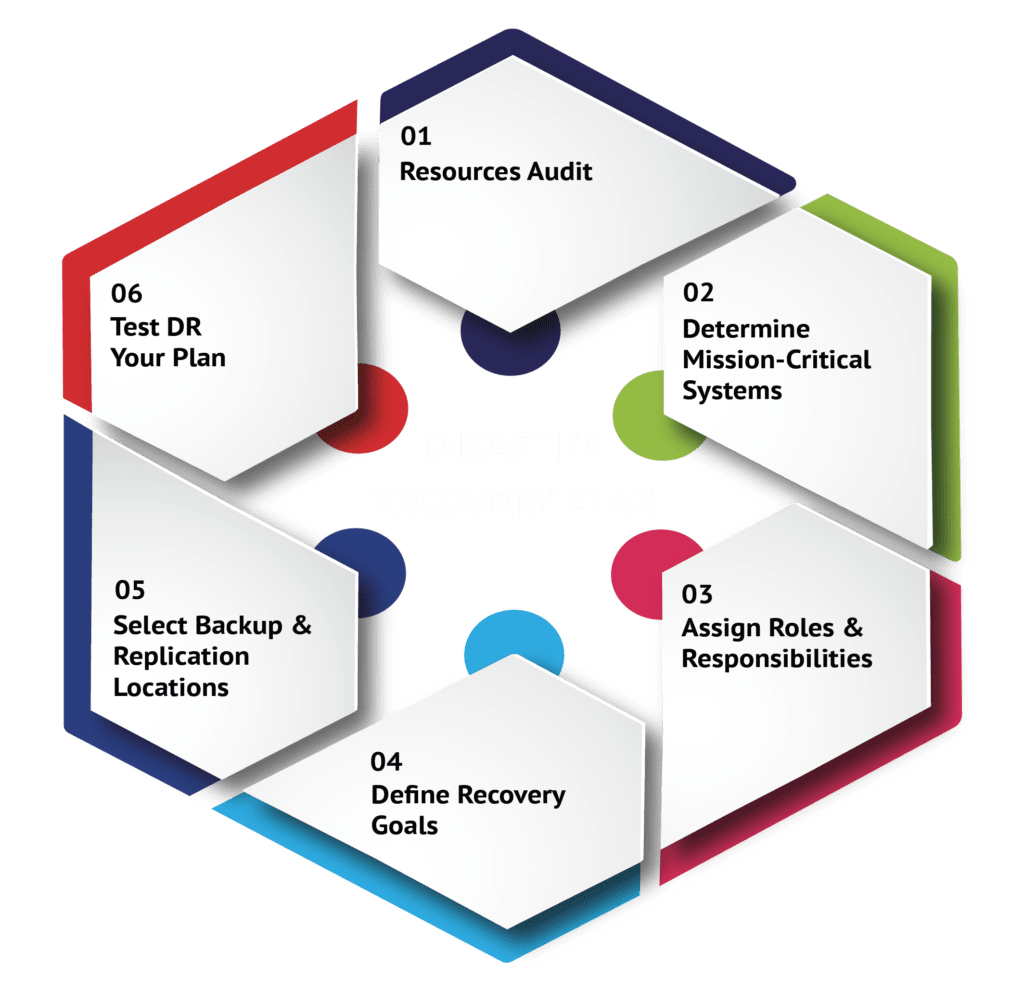
The steps below outline the high level the tasks you will typically need to perform to develop a robust DR plan.
Step 1: Complete an IT resources audit
An audit should be performed of all business-critical systems including as much detail as possible. Information should include items such as machine and storage capacity specifications, OS versions, installed applications and versions, machine location. In addition to servers, it is important not to neglect the corporate network components including diagrams of its topology plus details of vital configuration parameters. Corporate end point devices such as employee mobile device and laptop should also be included. By creating an inventory of all the IT resources on your network and what application and data each resource holds you can begin to consolidate and streamline everything to make backup and recovery easier in the future.
Step 2: Determine a hierarchy of mission-critical systems
DR planning provides a good opportunity to look in detail at your business processes to truly determine which elements are crucial to maintain operations. It is likely that your business processes and stores a lot more data than you expected including a lot of redundant data that is not crucial for maintaining business operations. During your IT resources audit, you will probably discover several data sets that are not important and therefore not worthy of consuming backup resources. Determining which systems and applications are mission-critical will call upon your cost of downtime analysis which is turn will determine what RTO/RPO and data protect method you will need to employ.
Step 3: Establish roles and responsibilities
Every employee in the organization should have a role to play in your disaster recovery plan. Something as simple as reporting a cybersecurity vulnerability to someone with more seniority or know-how to enact the DR plan can prove to be critical. Having a clearly documented list of roles and responsibilities will make your DR plan much more effective.
Step 4: Define your recovery goals
It can be very easy to fall into the trap of determining recovery goals for your most critical systems and then applying this measure as the lowest common denominator for all of your recovery targets. Setting overly ambitious RTO/RPO targets on system will put unnecessary pressure on your internal team which may well be detrimental to the overall recovery process. We will look at risk analysis and the appropriate choice of recovery type and recovery targets in sections 4 and 5.
Step 5: Select and document your backup and replication locations
There are a wide variety of choices when choosing a location for your data backups and system replications. If these are offsite and/or managed by 3rd party organizations then details of their location including key points of contact should be included in the plan. In addition, the procurement process for replacement hardware should be planned and documented. If using a 3rd party for recovery system provision questions should be asked regarding their lead times for provision of equipment, and their customer allocation priority in the case of a state-wide event impacting many companies. Specifically, will they have enough hardware, and will allocation be first come, first serve, or based on another customer tiering structure.
Step 6: Develop and document a DR test plan
“To believe in one’s backups is one thing. To have to use them is another. If you haven’t tested your recoveries, you do not really have backups.” The importance of genuinely testing you DR procedures cannot be stressed highly enough. Testing without automation is a difficult and time-consuming task and a key reason why so many companies fail to test their recovery procedures on a regular basis, if at all. We look at DR testing in more detail in sections 6 and 7.
4. Selecting recovery options
A suitable recovery strategy will be required for each of the risk types identified as relevant and significant to your organization. RPO is a key factor used for determining the frequency of data backup that will be required to recover critical data in case of a disaster. Systems where transactional integrity is vitally important will often require replicated systems with Continuous Data Protection (CDP) operating as a failover-failback pair, or as part of a multi-node cluster configuration. Therefore, for each system within your business process architecture, your DRP needs to specify whether system recovery will be accomplished by restoring files from a recent backup, or through transferring services to a replicated system running within a live DR environment. In the case where system recovery involves restoration from a backup, there is a further choice to be made as to whether you repair and rebuild your original system, or perform restoration of the operating system, applications, and data to a dissimilar platform. The latter choice presents additional specific challenges which we will address later in this section.
Backup vs. Replication - Key differences and usage scenarios
There can be some confusion around the terms Backup and Replication. They are frequently seen either as interchangeable terms, or alternatively as an either/or approach within a DRP. Backup and recovery, and replication are all crucial parts of a complete disaster recovery plan. Each plays their part in keeping your systems protected, but the roles they play are different. First let us examine the role of backups as part of disaster recovery planning.
The Importance of Backups
Backups are designed to give you a long term, consistent backup of your data. Backups could be used to recover from your most recent backup after a server failure or be used to provide a granular recovery of a single file that has been accidentally deleted. Backups can also be deployed longer term to meet compliance targets. Essentially, backups are your last line of defence, and they focus on a balance between your recovery points and recovery time. In addition, backups can be air-gapped (isolated) away from your production environment to further protect your systems against malicious software. Cybercriminals are aware of the importance of backups in your defence against ransomware, so they are often targeting and compromising backups first before issuing their demands. Therefore, isolated backups which are also immutable are now becoming a key part of many cyber security strategies. A key point to remember your business applications, they do not contain the complete operating system and disk storage infrastructure information required to completely rebuild and re-provision a compromised system.
Introducing Replication
While backup and recovery software can normally recover your systems and data quickly, the RTO will typically be slower compared to using replication as part of the process. This is because systems will need to be provisioned first before applications and data are restored which is a time-consuming process.
Replication Software
Replication software creates a live copy of your business-critical systems which can include the complete system configuration and regularly synchronises this data between your primary production system and secondary copy of that system. If disaster strikes, you can quickly transfer your business from running on your primary copy to your secondary copy, a process known as failover. This minimises the downtime to your business (RTOs) and potential data loss, as the syncs between the two systems are likely to be much more frequent than your full backups, known as your RPOs. System failover and failback can be automated to further reduce system downtime and, in many cases, a RTO close to zero may be achieved such that any outage is not discernible to system users. Cristie Recovery software can detect failures and provide failover/failback automation through the Cristie Virtual Appliance (VA) software configuration. Essentially, replication is more focused on your business continuity and minimising the impact of a disaster on your business, whilst you recover your secondary systems from your backups.
Cristie CloneManager™ Software
Cristie CloneManager software creates synchronised, replicated copies of your business-critical machines to keep your business running with minimal downtime and impact to your business during a DR scenario. The syncs can be set on a user defined schedule to lower your RPOs, or the loss in data between the two systems, down to minutes. CloneManager also includes features such as Automated Failover and Failback to automate the failover process and further reduce your RTOs and downtime to your business. Enhanced testing enables testing of your replicated copies away from the production environment without affecting the synchronisation process, giving you total confidence in your disaster recovery plan.
Maintaining replication mobility to avoid vendor lock-in
The advent of virtualization technology and cloud computing has provided organizations with a wide range of choices when selecting a target platform for system replication. Physical systems no longer must be replicated to similar physical systems running within a DR location. In cases where high performance computing is required, like-for-like, physical-to-physical system replication may be essential. However, in many cases, replication of physical machines to virtual or cloud targets for the purposes of disaster recovery is now a very viable option, and for many organizations this is becoming standard practice. The task of configuring a virtual or cloud-based replication target and then managing the replication jobs for multiple machines can seem a daunting task. Many cloud-backup and replication service vendors offer free migration and replication tools to assist customers with the on-boarding process of replicating systems to a virtual cloud environment. At first glance this may seem to be a very valuable facility. The downside is that the tools provided are generally designed to replicate systems only to the vendors specific cloud environment, so in the sense of replication mobility many of these tools are unidirectional. Of course, from the vendors perspective, their interest lies in attracting and maintaining customers which has the potential downside of creating a vendor lock-in scenario for the customer. To ensure maximum protection and freedom of cloud vendor selection, your DRP should strive to achieve full replication mobility meaning that your DR infrastructure should be able to replicate vital systems in any direction, to and from physical, virtual and cloud targets with full independency regarding the choice of cloud provider. The Cristie VA provides this capability allowing full freedom to move your DR systems between vendors and platform types.
Replication target selection on-premises, cloud, co-location, or hybrid
On-premises
Probably the biggest advantage of on-premises system replication is data protection. Because data is stored locally on your premises, you have full control over it and its security. Sensitive data does not have to leave the company which can be a decisive advantage, especially when it comes to compliance issues and ensuring data sovereignty. Another key advantage is performance. With any offsite replication solution your recovery performance will be governed by the internet, SD-WAN or MPLS connection you have to your colocation or cloud provider, which in some cases may be far lower than the Probably the biggest advantage of on-premises system replication is data protection. Because data is stored locally on your premises, you have full control over it and its security. Sensitive data does not have to leave the company which can be a decisive advantage, especially when it comes to compliance issues and ensuring data sovereignty. Another key advantage is performance. With any offsite replication solution your recovery performance will be governed by the internet, SD-WAN or MPLS connection you have to your colocation or cloud provider, which in some cases may be far lower than the performance available within your internal network. In addition, your internal network should be accessible anytime, ensuring that systems are replicated regardless of the state of your internet connection. Also, if your business does not rely on the internet or cloud-based services for backup and replication, you may not need to pay for such a high-speed connection, lowering monthly internet costs. As, discussed previously, the risks of proximity to your production system in the event of a local or natural disaster event do need to be carefully considered when choosing an on-premises DR solution.
Pros
- Ease of access and deployment flexibility
- Complete control over data security and data sovereignty
- System and network performance advantages
- Potentially lower internet costs
Cons
- Capex costs
- Administration overheads
- Maintenance costs
- Susceptible to natural or other local disaster scenarios
Colocation
center that has been purpose-built to ensure uptime reliability for multiple customers. Colocation data centers rent space, where secure cages and private suites reside in an ideal IT environment to maintain companies’ physical IT assets. Finding the right colocation provider can offer tremendous advantages in terms of carrier-neutral network connectivity, cloud on-boarding for hybrid connectivity, and multi-cloud connectivity via a solid network infrastructure. In most cases, colocation data centers can offer their customers a superior IT solution at a lower total cost with fewer disadvantages than on-premises solutions, although initial setup costs are usually higher. Each client is using systems of their own which comes with certain advantages and drawbacks. Since you are not the owner of the data center, you may have to follow certain regulations applied to your tenancy that may restrict access at certain periods of time. Performing equipment maintenance will require a trip to your colocation data center location, so it is important to understand access rules and ensure these requirements meet the needs of your business. In many instances, tenants can utilize concierge services and the colocation facility in-house IT experts for maintenance and operational tasks, thereby avoiding unnecessary travel to the data center. Overall, for mid-size to large enterprise businesses, the advantages of colocation should outweigh the initial setup costs to provide a good combination of performance and affordability. This is especially true when the partner you select can provide high-touch customer service to address any concerns with your deployment.
Pros
- Time And Cost Savings.
- No requirement for additional server and infrastructure facilities
- Reduced overall cost of IT management
- Avoid power capacity challenges
- Extensive connectivity
- Flexibility
- Enhanced security both physical and cyber
Cons
- Initial costs are higher
- Capex costs
- Potential for less control
- Restrictions on maintenance with regards to time or resources
- Finding the right provider in terms of proximity, pricing, and services
Hybrid
Cloud computing is very well established, yet many companies are still afraid to migrate their systems and data to this environment. The most frequent concerns include the confidentiality of information, the quality of services, and the performance that business applications will have after migration. Developing a hybrid IT infrastructure can serve as a bridge to alleviate some of these concerns with a ‘best of both worlds’ solution, enabling companies to choose what they want to move to the public cloud, what to keep on-premises, and decide which cloud backup and replication services to use for what purpose. In addition, companies can include a private cloud within this architecture which is an internal cloud computing environment offering all the scalability of public cloud services but dedicated exclusively to, and accessible only by the company. Both the on-premises, public and private cloud infrastructure can work independently or be connected as required. For example, you may choose to replicate a critical workload, with strong security requirements or compliance to your private cloud with less critical processes taking advantage of public cloud services. This gives the company total control over the infrastructure and the DR application stack.
Pros
- Flexibility
- Scalability and deployment
- Increased Mobility
- Increased Data Security
Cons
- Difficult to implement
- More expensive than public cloud
- File compatibility between private and public platforms
- Potential of losing visibility of your information
Replication target types
Physical machines
Operating systems running on physical machines are tightly coupled to the underlying hardware through drivers which are specific to the peripherals used on the system board. Examples include storage controllers, graphics adapters and network adapters. If a physical replication target machine is not identical to the original source system, then the system replication image may fail to boot on the target machine due to a mismatch of one or more boot critical system level drivers. This is a situation that many IT systems administrators will be familiar with that involves a certain amount of difficulty and time to provision the target system into a boot ready state before the applications and data can be accessed.
Overcoming the headache of recovery to dissimilar hardware
In contrast, using Cristie Recovery software provides a simple to use tool to recover your whole system to any hardware, virtual or cloud platform. Our software creates a machine configuration file which is saved with your backup. This configuration file contains all the information required to prepare for recovery on any comparable target. Systems can be recovered as a clone of the original system in one hit, including a point in time recovery. This means there is no time wasted trying to find software; everything you will need is contained in the backup. If you are recovering to different hardware, we will take care of any new driver injection automatically before the initial boot of the target recovery system. Likewise, if you are recovering into a virtual or cloud environment, we can fully automate the creation of the VM with the same CPU, RAM and disk that was available on the original physical machine.
Running Virtual machines (VMs)
Virtual machines (VMs) typically refer to separate operating system (OS) installations running on a single computer, with each OS being allocated a share of the computer’s system resources. For example, a Linux VM may be installed on top of your Windows PC. Multiple OS installations can coexist on the same physical machine at the same time, so long as the machine has powerful enough hardware. This makes VMs a convenient way to extend desktop and server environments. Other benefits of VMs include simple and fast provisioning, high availability, and great scalability. From a DR perspective it is the rapid provisioning and scalability that make VMs such an attractive replication target. Through the Cristie Virtual Appliance (VA) it is possible to replicate or recover systems from physical or cloud sources to virtual machines with the option of scaling VM resources to either match the source system or modify specific resources up or down during provisioning. For example, you may wish to replicate to a running VM with lower system resources than the source machine for DR purposes on the basis that you can accept slightly lower performance during a system failover to save costs as this will be a temporary situation until operations can failback to the normal production environment.
Virtual disk image files
So far, we have discussed replication targets that are termed ‘online’ targets since they are running machines ready to instantly take over from the primary system in the case of a system failure or disaster scenario. The advantage of ‘online’ replication targets is that they are ready to run and can takeover operations very quickly. The downside is that they are consuming physical or virtual compute resources continuously while merely waiting for an incident to happen. To overcome this overhead of maintaining running standby machines and alternative exists in the form of virtual disk image files. Virtual machines can be captured as a complete image in the same way that a system drive in a physical machine can be captured as a single disk image. The image file contains everything including the OS configuration, applications, and all data. System replication can be performed to a virtual disk image file stored within a private or public cloud environment rather than to a running machine. This has a significant cost advantage as only the cost of cloud storage is required to maintain these image files rather than storage plus compute resources. The disadvantage is that they are slower to bring online than a running machine, but for many DR scenarios the RTO they provide is sufficient. Cristie replication solutions provide both online and offline replication capabilities with support for all common system image standards including .vhdx, .qcow2 and .vmdk file formats via the Cristie VA.
5. Identifying recovery priority for applications
Priorities for recovery (shared services and infra-structure)
A robust DRP should not neglect the importance of the underlying corporate network. An organization cannot function properly without network services being available to move data within the infrastructure. Therefore, the importance of network services cannot be underestimated; a solid DRP should also include network disaster recovery planning and cover ways to reduce the risk of network failure. As IT infrastructure continues to move away from a fixed hardware-centric topology towards software defined architectures, network profiles can more easily form part of your regular backup set to include network configuration files, including the initial parameters and settings for configuring network devices following any infrastructure disaster.
Priority of applications groups to be recovered
A key part of any DRP will be the recovery priority list for business process applications. By taking a tiered approach, disaster recovery planners can structure the recovery process to cut downtime and protect high-priority systems. Conceptually, the recovery point objectives (RPO) and recovery time objectives (RTO) calculated during the ‘cost of downtime’ analysis stage can serve as a good starting point for determining application recovery priorities.
Order of systems to be recovered within application groups
Clearly many applications will have dependencies on other applications, so the recovery priority list will most likely contain application groups which need to be recovered and brought online in a specific sequence to ensure that business process operations are able to flow smoothly without any bottlenecks. It is most likely that the first system and application group to be restored will contain fundamental infrastructure servers such as the domain controller which is required at the outset to respond to security authentication requests and verify users on each domain of a computer network. This controller is the gatekeeper for allowing host access to all domain resources.
6. Manual or automated recovery?
Should I recovery manually?
If you have a solid DRP in place, great. But if you are considering recovering your systems manually, the process might be a lot more complex than you think. While it is not impossible to recover your systems manually, you will need specific skill sets in managing operating systems, applications, networks, and storage as well as a lot of time. Typically, a full manual rebuild of a server with applications will take anything from two to eight hours, in addition to the time needed to restore the data. What’s more, manual recoveries tend to be unplanned, meaning you will be working against the clock in what might already be a highly stressful situation. Let us consider a manual restore process step by step.
- To start, you will need to identify the system to install on (physical, virtual or cloud). Bear in mind that if it is virtual or cloud you will need to manually create the VM, manually install the OS and run any patch updates, before moving on to locating install media for any applications.
- You will then need to verify that these application versions work with the OS version installed, before moving on to installing the recovery software and other programmes and applications. Finally, you can start to restore your data.
- Next, the machine name and IP address information will need to be changed before it is up and running again, but there are no guarantees that you will not have more problems after that.
Do I need an automation or orchestration product?
A manual recovery is a complex and time-consuming operation; compare it with the 10 to 15 minutes needed for a recovery with dedicated Bare Machine Recovery software which provides recovery automation and orchestration and hopefully you will agree the answer is a resounding “yes”.
7. Does it work
“According to Storage Magazine over 34% of companies do not test their backups and of those tested 77% found that tape backups failed to restore.According to Microsoft, 42% of attempted recoveries from tape backups in the past year have failed”A study done by National Archives & Records Administration in Washington concluded that “93% of companies that lost their data center for 10 days or more due to a disaster filed for bankruptcy within one year of the disaster.” Without proper testing of your backup set, results can be devastating for your organization should a disaster occur.
Regularly testing the recovery of your backups is crucial for three reasons; firstly, to identify any issues in advance, secondly to resolve them and finally to build confidence in your backups so that when you do need them for real, you can recover them quickly and efficiently to meet your RPOs and RTOs. The worst time to discover an issue with your backups or recovery process is when you are in the middle of a real-world disaster, relying on them most to get your business back up and running. Any problems that crop up during a disaster might not just delay your recovery, it might make your systems entirely unrecoverable. Unfortunately, regularly testing your servers manually is a time-consuming task, especially if you want to test across your whole data centre. Therefore, Cristie Software includes automated recovery testing functionality for all our system recovery customers as part of their licences.
Should I automate my testing?
If you are thinking about manual recovery testing, we say think carefully. Often, manual testing means that you can only effectively test your most critical systems. Using third party software? We have spoken to a lot of customers that have used third-party software to run their tests. Sometimes only a sample of the systems are tested and often that sample can be as low as 10-20%. This sample is then used to build a generalised picture of your backup health, which does not necessarily reflect the reality. When you use Cristie Software for your recovery testing, the process is automated and scheduled. It has enabled our customers to test the entirety of their server estates and be confident that they can recover any of their systems following a disaster.
DR Orchestration (Task automation, avoiding manual intervention)
DR orchestration can help in the orderly recovery of your server environment during an outage, making sure that your critical servers, applications, and data come online without incident and in an automated fashion. Cristie DR orchestration goes a step further than automated recoveries by giving you the ability to plan out and configure in advance all the stages required to get your business-critical systems back up and running after a server disaster. DR orchestration is included as one of the value-add features of the Cristie Virtual Appliance (VA). Both the VA and DR orchestration are free to use for all our system recovery and replication customers.
How orchestration works
Each orchestration job runs through a series of stages; and within each stage we can run as many different tasks as we like in parallel. For example, we can run replication or recovery tasks (with recoveries straight from your IBM Spectrum Protect, Dell Networker/Avamar or Cohesity backup server), reboots, scripts and reporting tasks that give you a detailed summary of the orchestration job. We can even do things like add in manual tasks, which will stop the automation whilst that task is performed (such as loading a tape drive), before continuing the orchestration once the task has been completed.
Using automation to save time and enhance your DR testing
All of this is designed to use automation to save you time when it matters most, minimising human interaction and the chance for human error in what has historically been a very manual process. DR Orchestration can also be used to enhance your DR testing regime, as not only are you able to test the recoveries, but you can also test the surrounding processes required to get your business back up and running. By being able to test the surrounding processes, like the system reboot, cross application integration or any post-boot scripts allows you to spot and fix any issues in advance on the entire process before you need them in a real-world DR scenario. This means that should you then need to recover for real, you can be confident in your ability to recover your business-critical systems quickly and easily.
Schedule your DR orchestration jobs in advance
As with our recovery testing feature, DR orchestration jobs can be configured and scheduled months in advance, with full email reporting on successes and failures that can be used for auditory, compliance, industry regulations, or if you are a service provider, as part of your SLA reporting to your customer.
DR recovery: Common failure scenarios
The DR recovery testing process will surface many failure scenarios which are certainly much more comfortable to deal with during the testing phase than they are under the pressure of a real emergency. A variety of technical and human inspired failures feature during testing, with the following being some of those most frequently reported by our software and/or experienced by our customers.
- Bad backup file(s):Often a corrupted backup file is detected that needs rectification and replacement
- Incomplete backup job: Incomplete file/folder selection during configuration of the backup job is another common reason for failure. This can be just an administrative oversight or in some cases poor internal communication being departments. For example, a business unit may request or install a new application, however, the responsibility for its backup may be missed due to incorrect assumptions between the business unit and the IT support team.
- Incompatible hardware: This is a common scenario when an organization has requested bare metal DR targets to be provided by the colocation or data center provider which require different or additional system level drivers for the recovery system to boot. This is a scenario which Cristie Recovery software can overcome in many cases using our automated dissimilar hardware technology.
- Network configuration: General network configuration errors are common especially when moving between physical and virtual targets.
Testing and reporting to meet compliance
In addition to building backup confidence internally, Cristie’s Recovery Testing can also help you to meet your governmental or industry based auditory and compliance measures which are commonplace within sectors such as healthcare and financial services (e.g., HIPPA and FSA regulations). All our automated recovery tests can be followed up with detailed email reporting on successes, failures, time taken to restore, and any problems encountered to give you a full record of your test results. In addition to these reports, we can also follow up the tests with further configurations, such as deleting successful tests to free up disk space and leaving failed recoveries in place while you investigate why the recovery failed.
8. Useful Resources
Links to useful planning tools and information sites
United States Government. Launched in February 2003, Ready is a National public service campaign designed to educate and empower the American people to prepare for, respond to and mitigate emergencies, including natural and man-made disasters. The goal of the campaign is to promote preparedness through public involvement.
IT Disaster Recovery Plan https://www.ready.gov/it-disaster-recovery-plan
Indiana University – Resources for IT Professionals Disaster recovery planning https://informationsecurity.iu.edu/resources-professionals/disaster-recovery-planning.html
IBM Example: Disaster recovery plan https://www.ibm.com/docs/en/i/7.1?topic=system-example-disaster-recovery-plan
EATON Downtime Cost Calculator https://powerquality.eaton.com/Products-services/Help-Me-Choose/DowntimeCostCalculator/Default.asp
9. Conclusions
Clearly disaster recovery planning and the process of disaster recovery itself are massively important and unsurprisingly daunting tasks for many organizations. The cost of provisioning systems for backup and redundancy is not insignificant, however, for many this cost becomes minuscule when compared to the cost of downtime, or even worse the far-reaching demands of a ransomware attack. Unlike most decisions in business process design, disaster recovery planning involves many trade-offs based upon risk analysis and the level of service that your customers, suppliers and employees require. Hopefully this guide has illustrated that both backup and replication have an important role to play in any robust DR strategy, and in many cases, it is unlikely that either would be used in isolation. Through advances in cloud computing, organizations now have a wide range of backup and replication target choices in terms of location and type; physical, virtual and cloud. Backup and replication mobility is also a key feature that should be written into any DRP to avoid vendor lock-in, or the potential for single points of failure in your redundancy plan. For further information regarding system recovery, replication and migration speak to the Cristie Software team who are always on hand to answer any questions.
10. References
1. [online] accessed 9 February 2022, https://www.ccn.com/facebooks-blackout-90-million-lost-revenue/
2. [online] accessed 9 February 2022, https://money.cnn.com/2016/09/07/technology/delta-computer-outage-cost
3. [online] accessed 9 February 2022, https://blogs.gartner.com/andrew-lerner/2014/07/16/the-cost-of-downtime/
4. [online] accessed 9 February 2022, https://www.usenix.org/conference/fast16/technical-sessions/presentation/schroeder
5. [online] accessed 9 February 2022, https://purplesec.us/resources/cyber-security-statistics/
6. [online] accessed 9 February 2022, https://en.wikipedia.org/wiki/2021_Texas_power_crisis
