


Déterminer le coût et la localisation de la dette technique en utilisant des mesures de vélocité dans une organisation DevOps.

La dette technique est définie (via Wikipedia) comme :
Le coût implicite du remaniement supplémentaire causé par le choix d'une solution facile maintenant au lieu d'utiliser une meilleure approche qui prendrait plus de temps.
Beaucoup supposent que cette dette se trouve uniquement dans le code et mesurent la complexité cyclomatique, la couverture de test et/ou utilisent un linter pour déterminer l'ampleur de la dette et son emplacement. Ces mesures fonctionnent bien, mais elles ne mettent pas en évidence les types de dettes (complexité, manque de tests, documentation insuffisante) qui causent les problèmes les plus importants ou par où il est préférable de commencer. Elles ne mesurent pas non plus les types de dettes qui sont plus difficiles à repérer, par exemple :
- Duplication des fonctionnalités
- L'ensemble de la structure est dupliqué, mais écrit différemment, peut-être dans une autre langue.
- Pas de conception pour le débogage
- Le débogage est difficile lorsqu'une erreur se produit à distance (site du client, service d'assurance qualité) en raison d'une mauvaise journalisation, d'un mauvais signalement des erreurs ou d'une variation entre la version et le débogage.
- Suite de test lente
- La suite de tests est longue à exécuter, ce qui entraîne un délai d'exécution plus élevé.
- ...
Il est possible que la définition standard de la dette technique soit quelque peu dépassée, aussi, chez Cristie, nous utilisons la définition suivante :
Le coût du travail supplémentaire causé par le choix d'une solution facile maintenant au lieu d'utiliser une meilleure approche qui prendrait plus de temps.
Cela nous donne un moyen de le découvrir :
- Si nous supposons que s'engager plus fréquemment est préférable
(...et nous disons que ça l'est, et encourageons les gens à le faire...) - alors la seule raison de ne pas s'engager plus fréquemment est que vous ne pouvez pas
- et la raison pour laquelle vous ne pouvez pas, nous la définissons comme étant notre dette technique car
- si nous avons refactorisé, architecturé ou autrement amélioré, alors vous pourriez.
Nous pouvons donc mesurer la dette technique comme :
Le temps passé sur les commits supérieurs à α écarts types qui contiennent un fichier qui s'éloigne de α écarts types de la normale.
C'est-à-dire, le temps supplémentaire sur les commits contenant des fichiers qui apparaissent régulièrement dans les commits qui prennent plus de temps.
Comprendre l'historique de nos livraisons
Nous avons écrit un script python qui traite les logs subversion et git pour produire :
- L'auteur de l'engagement
- Le temps d'activité depuis le dernier commit de l'auteur dans un repo quelconque
- Les fichiers dans ce commit
Nous avons ensuite normalisé ces commits pour chaque auteur et produit ce graphique :
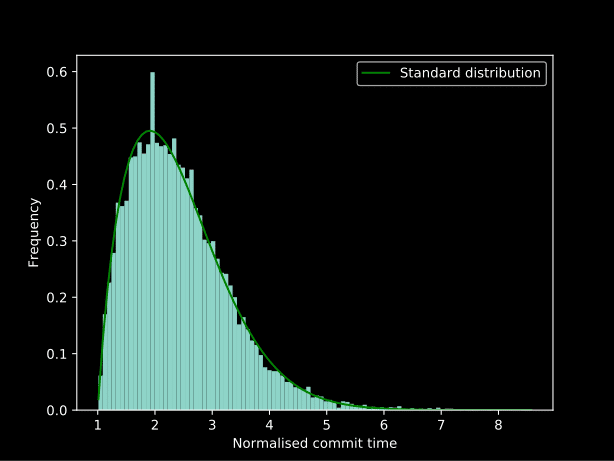
Quelques essais et erreurs (il y a définitivement une meilleure façon de le faire... mais les connaissances statistiques acquises au cours de l'expérimentation) ont permis de déterminer qu'en appliquant lambda x: np.log(x) ** 2 comme deux transformations Box-Cox simultanées donne un très proche de la distribution normale et en appliquant cette méthode à l'envers, on obtient la meilleure ligne d'ajustement dans le graphique ci-dessus :
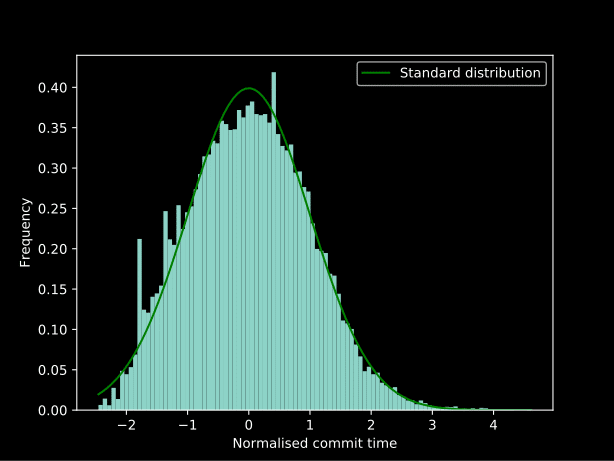
Dette technique
Nous pouvons maintenant déterminer la dette technique en calculant le z-score (une mesure de la "normalité" d'une population qui devrait être normale) pour chaque fichier :
[code lang=”python”]
def zscore(commits):
"Z-Score per-file for all files in commits"
perpath = collections.defaultdict(list)
for commit in commits:
for path in commit.paths:
perpath[path].append(commit.interval)
return {path : sum(perpath[path]) / math.sqrt(len(perpath[path]))}
[/code]
ce qui signifie que nous pouvons calculer les intérêts que nous payons sur la dette technique :
[code lang=”python”]
def debt(commits, deviation=1):
"Total debt for this series of commits"
scores = zscore(commits)
debt = 0
for commit in commits:
for path in commits.paths:
if scores[path] > deviation:
debt += commit.duration –
inverse(0) –
inverse(deviation)
return debt * 100.0 / sum(c.duration for c in commits)
[/code]
En utilisant une fenêtre glissante, nous pouvons produire un graphique de la dette technique dans le temps et trouver les fichiers qui y contribuent. Le graphique suivant montre la population de commits pour les fichiers à fort intérêt par rapport à la normale :
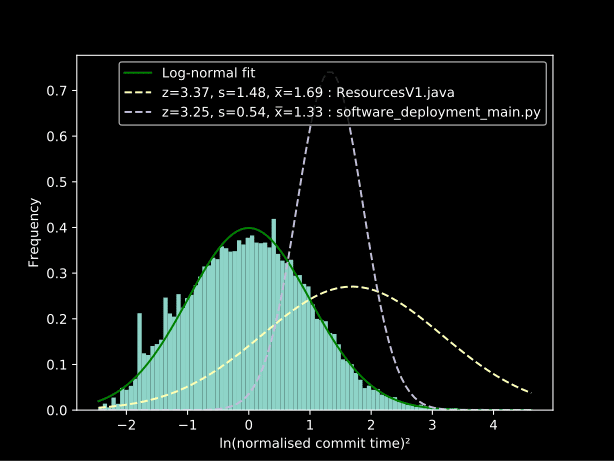
Résultats
La dette technique de 2018 oscille autour de 20 % :
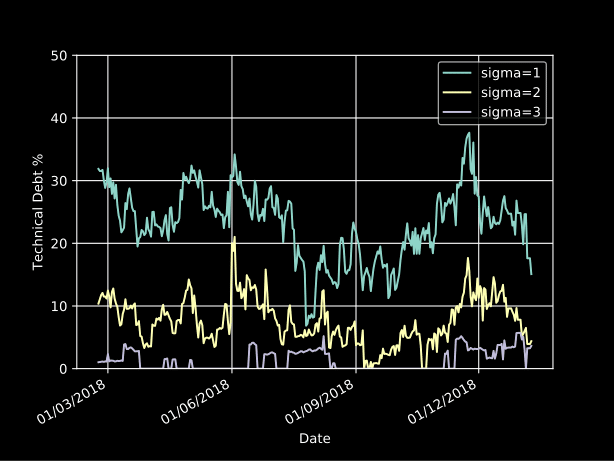
Plus important encore, cela nous donne une liste de fichiers sur lesquels nous devons travailler (édités pour protéger les innocents) :
| Z-Score | % d'engagements | Multiplicateur | Nom de fichier | |
|---|---|---|---|---|
| 3.18 | 1.66 % | 2.44x | Appliance Dockerfile | |
| 0.82 | 4.76 % | 2.14x | Code de licence pour un nouveau produit | |
| 2.94 | 0.98 % | 2.15x | API REST distante en python |
Dans les cas ci-dessus, nous avons convenu au sein de l'équipe qu'il s'agissait de zones problématiques. Notre diagnostic, dans l'ordre, était le suivant :
- Appliance Dockerfile
- La taille de l'appliance était trop importante, et le téléchargement des paquets requis depuis Nexus sur le réseau entraînait un délai important dans l'aller-retour.
Nous avons réduit de manière significative la taille de l'appliance pour contrer ce problème. - Code de licence pour un nouveau produit
- Ce code a été acheté et avait un certain nombre de problèmes :
- Compilation non concordante des architectures 32/64 bits et big/little endian
- Des fonctions dupliquées, mais portant un nom similaire, par ex.
CheckLicencevscheck_licence - Noms trompeurs (
dsUint32_test en fait juste unint...)
Nous avons remanié ce code en profondeur et ajouté des tests pour clarifier ce problème.
- API REST distante en python
- Ce système présentait une complexité cyclique élevée et une faible documentation mais, surtout, un délai d'exécution élevé des tests d'intégration.
Cette situation a été améliorée en supprimant certaines des étapes du test d'intégration effectuées pour chaque test.
Arguments contre cette approche
Qu'en est-il des choses qui ne vont pas dans le contrôle de version ?
Tout d'abord... tout doit être sous contrôle de version ! C'est facile. Bien sûr, il y a toujours des actions qui ne le sont pas - mais elles sont soit indépendantes du commit actuel (et n'affecteront donc pas les données lorsqu'elles sont prises en masse), soit elles affectent le commit actuel - auquel cas elles constituent une dette technique.
Et si certaines personnes prenaient plus de précautions que d'autres ?
Nous normalisons sur une base par auteur pour essayer de rendre nos données sur le code et le processus, plutôt que sur l'individu.
Les intérêts ne sont payés que lorsque le code est actif, donc une baisse des intérêts peut simplement signifier que le code actif est meilleur.
C'est très vrai... et c'est définitivement un problème. Le code inactif avec une dette technique élevée représente un risque mais ne freine pas vraiment les choses... pour l'instant. C'est là que les mesures secondaires (complexité, couverture et linting) peuvent être utiles - en particulier si un lien avec la mesure empirique de la dette peut être trouvé. ...surveillez cet espace.
