
Una situación de catástrofe puede venir de cualquier parte, ya sea una tormenta que inunda la sede, una pandemia que obliga al personal a trabajar a distancia o un ciberataque que deja los sistemas comprometidos, es importante en situaciones como éstas tener planes preparados para garantizar que su personal y su empresa puedan seguir funcionando. Aunque no sea a pleno rendimiento, es vital para la supervivencia de su empresa alcanzar una posición en la que pueda atender a sus clientes con un nivel aceptable de experiencia de servicio lo antes posible. El acto de desarrollar estrategias para mitigar los riesgos de sucesos inesperados es el núcleo de la gestión de la continuidad empresarial y un proceso vital que todas las empresas deberían emprender. Desgraciadamente, los estudios demuestran que tan sólo el 35% de las pequeñas empresas cuentan con planes de recuperación adecuados y que sólo el 10% de las que no tienen ningún proceso de recuperación sobrevivirán a un incidente grave. Un Plan de Recuperación de Desastres (DRP) del sistema es un subconjunto del plan general de continuidad de negocio, y el proceso de recuperación del sistema es el tema en el que nos centraremos aquí. El plan de RD es un planteamiento documentado con instrucciones sobre cómo responder a incidentes imprevistos que implica restaurar sistemas de apoyo vitales, como instalaciones de servidores, activos informáticos y otros sistemas y datos de infraestructuras críticas. El objetivo de un plan de recuperación ante desastres es minimizar el tiempo de inactividad de la empresa y los servicios y restablecer el funcionamiento normal de las operaciones técnicas en el plazo más breve posible. Al igual que en muchas áreas de la estrategia y la planificación empresarial, a la hora de crear un plan de recuperación en caso de catástrofe hay que sopesar los riesgos y los costes del tiempo de inactividad de los elementos clave de las operaciones de la empresa.

El tiempo de inactividad de los sistemas informáticos críticos afectará de algún modo al flujo normal de los procesos empresariales y, en casi todos los casos, supondrá una pérdida de ingresos. El coste exacto del tiempo de inactividad es, por supuesto, una cantidad muy difícil de medir. Entran en juego muchos factores, como el tamaño de la empresa, el sector, la duración real de la interrupción, el número de personas afectadas y la hora del día. Normalmente, las pérdidas son significativamente mayores por hora para las empresas que se basan en transacciones de datos de alto nivel, como los bancos y las tiendas minoristas en línea. Ha habido muchos ejemplos de alto perfil, incluido el apagón de 14 horas en 2019 que le costó a Facebook un estimado de 90 millones de dólares y en 20161, un apagón de cinco horas en un centro de operaciones de Delta Airlines causó 2,000 vuelos cancelados y una pérdida estimada de 150 millones de dólares2. Por supuesto, estos son líderes de la industria con enormes márgenes operativos y millones en el banco, pueden capear una tormenta financiera de un día mucho mejor que la mayoría. Las empresas más pequeñas pueden sufrir pérdidas menores durante un incidente grave; sin embargo, el impacto global puede ser mucho más perjudicial, incluso hasta el punto de llegar a la quiebra. La firma analista del sector Gartner realizó una encuesta sobre el coste del tiempo de inactividad en 2014 que determinó que el coste medio del tiempo de inactividad de TI era de 5.600 dólares por minuto. El informe mostró que, debido a las grandes diferencias en la forma en que operan las empresas, el tiempo de inactividad, en el extremo inferior, puede ser de hasta 140.000 dólares por hora, 300.000 dólares por hora en promedio y hasta 540.000 dólares por hora en el extremo superior3. Por supuesto, de aquí a 2022 estas cifras serán sin duda mucho más elevadas. Una forma elemental de determinar el coste del tiempo de inactividad para las secciones de su empresa es determinar cuántos empleados se han visto afectados, calcular su salario medio por hora y, a continuación, decidir el impacto del tiempo de inactividad en su productividad. Por ejemplo, si toda su línea de producción está parada, el impacto en su departamento de fabricación sería del 100%, entonces aplique la fórmula Coste del tiempo de inactividad = (número de empleados afectados) x (impacto en la productividad) x (salario medio por hora)Además, hay varios costes menos tangibles del tiempo de inactividad, como el impacto en la moral de los empleados, su reputación, la marca y la lealtad de los clientes, que deben tenerse en cuenta. Más allá del valor para la planificación de la recuperación ante desastres y la creación de resistencia operativa, el análisis del coste del tiempo de inactividad puede ayudarle a pensar estratégicamente sobre su modelo de negocio y le permite comprender mejor su empresa desde un punto de vista táctico.

Para cada función empresarial es importante determinar los objetivos de tiempo de recuperación (RTO) y los objetivos de punto de recuperación (RPO) aceptables. En algunos casos, estos parámetros vendrán determinados por los Acuerdos de Nivel de Servicio específicos que se puedan tener con los clientes o incluso dentro de la organización. Como su nombre indica, el RTO define el tiempo máximo aceptable que se debe tardar en recuperar completamente un sistema a su estado de funcionamiento anterior al escenario de interrupción. RPO se define como la cantidad máxima de datos, medida en tiempo, que pueden perderse tras una recuperación de un desastre o evento comparable antes de que la pérdida de datos supere lo aceptable para la organización. Es importante que estos parámetros se calculen asumiendo el peor escenario posible. Muy a menudo, los cálculos de RTO se basan en estimaciones para una recuperación manual de un único sistema sin tener en cuenta la infraestructura subyacente. En muchas situaciones, como un ciberataque o una catástrofe natural, la realidad será que habrá que recuperar varios sistemas, lo que aumentará significativamente el RTO real y reforzará el hecho de que la recuperación manual de sistemas no es práctica. La recuperación de múltiples sistemas debe tenerse en cuenta para establecer una estimación real del RTO, y la automatización de la recuperación debe desempeñar un papel vital en el proceso de restauración. Acortar el RTO o reducir el RPO suele implicar mayores costes, de ahí la necesidad de realizar una evaluación de riesgos y un cálculo del coste del tiempo de inactividad para cada sistema que se desee proteger antes de establecer estos parámetros.
Antes de implantar un DRP, debe realizarse una evaluación de los riesgos y de todas las vulnerabilidades potenciales a las que puede ser propensa su empresa. La evaluación de riesgos de RD determina los riesgos potenciales para el funcionamiento de una organización derivados de catástrofes tanto naturales como provocadas por el hombre, con una estimación de la probabilidad de que se produzca cada escenario. A continuación, los resultados de estas estimaciones deben multiplicarse por el coste del tiempo de inactividad de cada escenario. El valor determinado define el nivel de protección que su organización debe considerar frente a una amenaza determinada. Sin embargo, en ciertos casos puede haber penalizaciones a más largo plazo que considerar, especialmente cuando la pérdida de datos podría significar contravenir las normativas de cumplimiento de la industria. Por ejemplo, si usted es una organización del sector sanitario que se rige por la normativa HIPPA para la protección de la información sanitaria electrónica protegida (ePHI), que exige específicamente una copia de seguridad segura de "copias exactas recuperables de la información sanitaria electrónica protegida", y una inundación acaba con todos sus datos, los problemas de cumplimiento derivados de la destrucción de los registros persistirán durante meses o incluso años si no disponía de un sitio seguro de copia de seguridad. Independientemente de que la catástrofe sea natural o provocada por el hombre, también es importante identificar y planificar las situaciones en las que, además de la pérdida de sistemas, es posible que no tenga acceso a los recursos y el personal a los que está acostumbrado durante las operaciones comerciales normales.

Una catástrofe natural suele afectar al acceso a los edificios y a las infraestructuras de apoyo, por lo que debe considerarse la posibilidad de replicar todo el emplazamiento si la evaluación de riesgos indica que la probabilidad de que se produzca un suceso de este tipo es suficiente. La ubicación del sitio de replicación deberá tenerse en cuenta si se encuentra en una zona propensa a los fenómenos naturales. Por ejemplo, considere una empresa financiera situada en San Francisco, California. Las finanzas son un sector estrictamente regulado y las empresas deben mantener registros de una manera muy específica. Además, como la empresa está en California, existe un elevado riesgo de terremotos. Teniendo en cuenta estas limitaciones, deben asegurarse de que los centros de datos tienen copias de seguridad para evitar multas si se destruye un centro de datos, y que los sitios de replicación están en otros lugares que son menos susceptibles a los terremotos. Del mismo modo, si se encuentra en una llanura inundable, la replicación local in situ probablemente no sea la opción más segura.
La forma más común de error humano es el borrado accidental de archivos o carpetas. Para mitigar estas situaciones, deben programarse copias de seguridad periódicas de los volúmenes de datos importantes, de modo que los elementos eliminados puedan restaurarse a partir de una copia puntual adecuada. Por supuesto, los humanos pueden ir mucho más allá del borrado accidental de archivos y realizar tareas no deseadas como el apagado accidental del sistema, la desconexión de cables de red, la introducción incorrecta de datos y, por desgracia, son su mayor riesgo a la hora de facilitar la ciberdelincuencia. El 98% de los ciberataques se basan en la ingeniería social5 para obtener datos de inicio de sesión y personales, o para distribuir una carga de malware a través del personal que abre archivos adjuntos maliciosos. Aparte de los riesgos cibernéticos que presentan los humanos, que son un tema digno de mucho más debate del que se puede tratar aquí, los errores como los cierres accidentales y los borrados de archivos se pueden reducir limitando el acceso físico al sistema al personal necesario y, del mismo modo, limitando el acceso de inicio de sesión sólo al personal esencial para sus sistemas más críticos.
Los cortes de energía imprevistos provocarán un apagado imprevisto de los sistemas, lo que puede ocasionar la pérdida de transacciones o la corrupción de archivos de datos. Como mínimo, los sistemas críticos deben contar con una fuente de alimentación ininterrumpida (SAI) que proporcione energía de emergencia cuando falle la fuente de alimentación de entrada o la red eléctrica. El SAI será capaz de suministrar energía durante un tiempo limitado para facilitar un apagado suave, o para permitir que se aplique energía alternativa procedente de generadores de reserva, si están disponibles. La replicación en la nube o en un emplazamiento físico independiente puede proporcionar una conmutación por error en caso de fallo de la alimentación eléctrica; sin embargo, el acceso a la red y los sistemas de comunicación también pueden verse afectados por el apagón, por lo que deben tenerse en cuenta en el DRP métodos alternativos de acceso a la red.
Los fallos del sistema debidos al hardware subyacente pueden ser progresivos o instantáneos y catastróficos. Las unidades de disco duro (HDD), debido a sus piezas mecánicas móviles, presentan muy a menudo un patrón de fallo progresivo que puede mitigarse aplicando mecanismos de protección de datos como los distintos niveles de RAID disponibles. Del mismo modo, aunque no tienen partes móviles, el almacenamiento basado en flash y las unidades SSD tienen una vida útil finita, además de características de desgaste que limitan su capacidad utilizable con el tiempo. Las SSD son relativamente nuevas en el mercado, por lo que los fabricantes aún están tratando de determinar su vida útil. Las estimaciones actuales hablan de un límite de 10 años para las SSD, aunque en la práctica la vida media de estas unidades parece ser más corta. Los investigadores de un estudio conjunto de Google y la Universidad de Toronto probaron las SSD durante varios años y descubrieron que se sustituían aproximadamente un 25% menos que los discos duros4. Del mismo modo, la memoria del sistema puede presentar fallos progresivos; sin embargo, debido al hecho de que la memoria del sistema suele contener instrucciones de código de aplicación y datos operativos, la mayoría de los fallos de memoria provocarán un bloqueo de la aplicación o del sistema operativo. Los fallos a nivel de placa del sistema suelen ser catastróficos y obligan a sustituir la placa afectada o a recuperar una imagen completa del sistema en una máquina física de sustitución. A menos que el hardware de la máquina de reemplazo sea idéntico al original, el proceso de recuperación puede encontrar problemas debido a diferencias en los controladores críticos de arranque, lo que resulta en una larga intervención de los equipos de soporte de TI. En la sección 3 se describe una solución para recuperar sin problemas sistemas en hardware distinto.
Los virus informáticos son casi siempre invisibles. Sin un software antivirus instalado en sus sistemas y dispositivos de punto final, es posible que no sepa que tiene uno. El daño causado por los virus puede variar, pero los menos dañinos suelen poder eliminarse o ponerse en cuarentena con el software antivirus que haya elegido. El proceso suele seguir la secuencia de pasos que se indica a continuación.
Un punto clave que hay que entender es que los sistemas tradicionales de protección contra el malware, incluidos los cortafuegos y el software antivirus, utilizan una técnica de protección conocida como lista negra. Se trata de una técnica eficaz, pero que requiere mucho tiempo, tanto para las empresas de software de seguridad, que deben mantener constantemente archivos de definiciones para detectar y aislar todos los códigos maliciosos conocidos, como para el personal informático, que debe asegurarse de que todos los parches del sistema y los archivos de definiciones se mantienen actualizados. Las cargas útiles de los programas maliciosos y los virus están diseñadas para explotar las vulnerabilidades que se han encontrado en la pila tecnológica, ya sea en un sistema operativo, en la infraestructura de red, en una aplicación o en cualquier otro punto intermedio. Aquí radica el principal fallo del enfoque de las listas negras: se están parcheando constantemente agujeros de seguridad que ya se conocen y están siendo explotados; de ahí que los equipos de seguridad informática estén siempre a la zaga de la ciberdelincuencia.El enfoque tradicional de las listas negras es reactivo y permite que códigos de malware nuevos y desconocidos se infiltren y propaguen sin ser detectados antes de causar estragos. Estas nuevas vulnerabilidades se conocen como exploits de "día cero". Hasta que se mitiguen estas vulnerabilidades, los piratas informáticos pueden seguir explotándolas para afectar negativamente a las aplicaciones del sistema, los datos de la empresa y otros ordenadores de la red.
Un ciberataque es un ataque orquestado contra la red, los sistemas, la infraestructura y los datos de una empresa que cuenta con la intervención manual de un individuo o un equipo de hackers. Los objetivos del atacante suelen ser paralizar sistemas empresariales vitales bloqueando y/o cifrando los sistemas y datos que necesitan para funcionar. A continuación, se pide un rescate bajo la premisa de que se proporcionará una clave de descifrado previo pago. Una tendencia de ataque más reciente es la exfiltración adicional de información confidencial de la empresa e información de identificación personal (PII) bajo la amenaza de filtrar esta información públicamente, o para su venta a través de la web oscura. Muy a menudo, un ciberataque se inicia mediante la entrega de un virus informático (código malicioso), como se ha descrito anteriormente. Por lo general, el virus se envía a través de un correo electrónico de phishing que engaña al destinatario para que descargue un archivo adjunto que contiene el código malicioso en su ordenador o dispositivo. El código malicioso establece entonces una puerta trasera en la red informática e informa a los piratas informáticos de que se ha creado una vía de entrada. Otra posibilidad es que los piratas informáticos intenten explotar vulnerabilidades desconocidas (de día cero) en elementos de una red corporativa, como conmutadores y enrutadores, sistemas operativos informáticos o, de hecho, cualquier dispositivo conectado a la red que pueda proporcionar una puerta de entrada no detectada.
Algunas empresas siguen respondiendo con una PBX (centralita privada), mientras que muchas han optado por la VoIP (voz sobre protocolo de Internet) basada en Internet o una plataforma de comunicaciones unificadas como servicio (UCaaS) basada en la nube. Está claro que los cortes de electricidad y de red pueden afectar a los sistemas de comunicaciones, pero no es raro que un ciberataque deje inoperativa la infraestructura de comunicaciones de una empresa. Las empresas que han dejado atrás la centralita tradicional y han optado por una centralita basada en la nube se encuentran en una posición mucho mejor en términos de disponibilidad de las comunicaciones debido a la redundancia integrada que ofrecen estos sistemas. No obstante, es importante que las empresas dispongan de plataformas de comunicaciones alternativas para, al menos, comunicarse internamente en caso de desastre. Existen numerosas opciones a tener en cuenta, muchas de las cuales son muy populares en las comunicaciones empresariales cotidianas, como Microsoft Teams, Skype, Zoom e incluso plataformas sociales como WhatsApp y Meta Platforms Messenger (antes Facebook). Como mínimo, los datos de contacto alternativos del personal clave deben documentarse en la sección de la cadena de mando de su DRP.
"En febrero de 2021, el estado de Texas sufrió una grave crisis eléctrica como consecuencia de tres fuertes tormentas invernales que azotaron Estados Unidos y cuyos daños se estimaron en al menos 195.000 millones de dólares, probablemente la catástrofe más cara de la historia del estado6. "
Un plan de recuperación ante desastres documenta los procedimientos y recursos que una organización utiliza para recuperarse de una interrupción importante de su infraestructura informática. La planificación de la recuperación en caso de catástrofe puede utilizar diversas herramientas en función de los activos existentes y los objetivos de recuperación de la organización. Los planes de RD suelen incluir los siguientes parámetros:
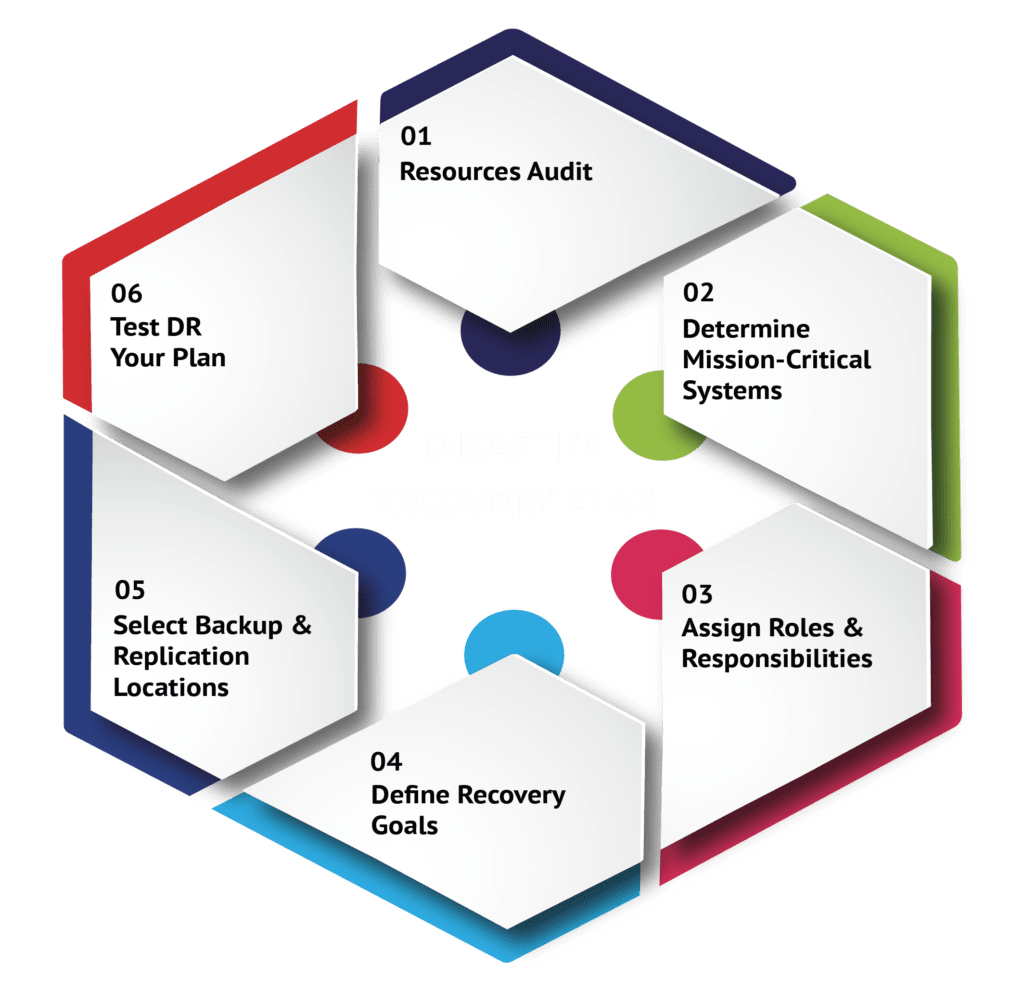
Los pasos que se indican a continuación describen a grandes rasgos las tareas que normalmente deberá realizar para desarrollar un plan de RD sólido.
Debe realizarse una auditoría de todos los sistemas críticos para la empresa, incluyendo el mayor detalle posible. La información debe incluir elementos como las especificaciones de la máquina y la capacidad de almacenamiento, las versiones del sistema operativo, las aplicaciones y versiones instaladas y la ubicación de la máquina. Además de los servidores, es importante no descuidar los componentes de la red corporativa, incluyendo diagramas de su topología y detalles de los parámetros de configuración vitales. También deben incluirse los dispositivos de punto final corporativos, como los dispositivos móviles y portátiles de los empleados. Al crear un inventario de todos los recursos informáticos de la red y de las aplicaciones y datos que contiene cada recurso, se puede empezar a consolidar y racionalizar todo para facilitar las copias de seguridad y la recuperación en el futuro.
La planificación de la DR ofrece una buena oportunidad para examinar en detalle sus procesos empresariales y determinar realmente qué elementos son cruciales para mantener las operaciones. Es probable que su empresa procese y almacene muchos más datos de los que esperaba, incluidos muchos datos redundantes que no son cruciales para mantener las operaciones comerciales. Durante su auditoría de recursos de TI, probablemente descubrirá varios conjuntos de datos que no son importantes y, por lo tanto, no merecen consumir recursos de copia de seguridad. Determinar qué sistemas y aplicaciones son de misión crítica requerirá un análisis del coste del tiempo de inactividad, que a su vez determinará qué método de RTO/RPO y de protección de datos deberá emplear.
Todos los empleados de la organización deben tener un papel que desempeñar en su plan de recuperación en caso de catástrofe. Algo tan sencillo como informar de una vulnerabilidad de ciberseguridad a alguien con más antigüedad o conocimientos para poner en marcha el plan de RD puede resultar crítico. Contar con una lista claramente documentada de funciones y responsabilidades hará que su plan de recuperación ante desastres sea mucho más eficaz.
Puede ser muy fácil caer en la trampa de determinar objetivos de recuperación para sus sistemas más críticos y luego aplicar esta medida como mínimo común denominador para todos sus objetivos de recuperación. Establecer objetivos RTO/RPO demasiado ambiciosos en el sistema ejercerá una presión innecesaria sobre su equipo interno, lo que puede resultar perjudicial para el proceso de recuperación general. Examinaremos el análisis de riesgos y la elección adecuada del tipo de recuperación y los objetivos de recuperación en las secciones 4 y 5.
Existe una gran variedad de opciones a la hora de elegir una ubicación para las copias de seguridad de los datos y las réplicas del sistema. Si se realizan fuera de las instalaciones o son gestionadas por terceros, el plan debe incluir información detallada sobre su ubicación y los puntos de contacto clave. Además, debe planificarse y documentarse el proceso de adquisición de hardware de sustitución. Si se recurre a un tercero para el suministro de sistemas de recuperación, habrá que preguntarse por los plazos de entrega de los equipos y la prioridad de asignación a los clientes en caso de que un suceso que afecte a todo el estado afecte a muchas empresas. En concreto, si dispondrán de suficiente hardware y si la asignación se hará por orden de llegada o en función de otra estructura de niveles de clientes.
"Creer en las copias de seguridad es una cosa. Otra es tener que utilizarlas. Si no has probado tus recuperaciones, no tienes realmente copias de seguridad". Nunca se insistirá lo suficiente en la importancia de probar realmente los procedimientos de recuperación de desastres. Las pruebas sin automatización son una tarea difícil y lenta, y una de las principales razones por las que muchas empresas no prueban sus procedimientos de recuperación con regularidad, si es que lo hacen. En las secciones 6 y 7 analizamos con más detalle las pruebas de RD.
Se requerirá una estrategia de recuperación adecuada para cada uno de los tipos de riesgo identificados como relevantes y significativos para su organización. El RPO es un factor clave para determinar la frecuencia de las copias de seguridad necesarias para recuperar datos críticos en caso de desastre. Los sistemas en los que la integridad transaccional es de vital importancia a menudo requerirán sistemas replicados con Protección Continua de Datos (CDP) que funcionen como un par failover-failback, o como parte de una configuración de clúster multinodo. Por lo tanto, para cada sistema dentro de su arquitectura de procesos de negocio, su DRP debe especificar si la recuperación del sistema se llevará a cabo mediante la restauración de archivos de una copia de seguridad reciente, o mediante la transferencia de servicios a un sistema replicado que se ejecuta dentro de un entorno de DR en vivo. En el caso de que la recuperación del sistema implique la restauración a partir de una copia de seguridad, habrá que decidir si se repara y reconstruye el sistema original o se restaura el sistema operativo, las aplicaciones y los datos en una plataforma distinta. Esta última opción presenta retos específicos adicionales que abordaremos más adelante en esta sección.
Puede haber cierta confusión en torno a los términos copia de seguridad y replicación. A menudo se consideran términos intercambiables, o bien como un enfoque alternativo dentro de un DRP. La copia de seguridad, la recuperación y la replicación son partes cruciales de un plan completo de recuperación ante desastres. Cada una desempeña su papel en la protección de los sistemas, pero sus funciones son diferentes. En primer lugar, examinemos el papel de las copias de seguridad como parte de la planificación de la recuperación de desastres.
Las copias de seguridad están diseñadas para proporcionarle una copia de seguridad consistente y a largo plazo de sus datos. Las copias de seguridad pueden utilizarse para recuperar la copia de seguridad más reciente tras un fallo del servidor o para recuperar de forma granular un único archivo borrado accidentalmente. Las copias de seguridad también pueden desplegarse a más largo plazo para cumplir los objetivos de conformidad. Esencialmente, las copias de seguridad son su última línea de defensa, y se centran en un equilibrio entre sus puntos de recuperación y el tiempo de recuperación. Además, las copias de seguridad pueden aislarse de su entorno de producción para proteger aún más sus sistemas frente al software malicioso. Los ciberdelincuentes son conscientes de la importancia de las copias de seguridad en su defensa contra el ransomware, por lo que a menudo atacan y comprometen primero las copias de seguridad antes de emitir sus demandas. Por lo tanto, las copias de seguridad aisladas que también son inmutables se están convirtiendo en una parte clave de muchas estrategias de ciberseguridad. Un punto clave para recordar sus aplicaciones de negocio, no contienen el sistema operativo completo y la información de la infraestructura de almacenamiento en disco necesaria para reconstruir completamente y volver a aprovisionar un sistema comprometido.
Aunque el software de copia de seguridad y recuperación normalmente puede recuperar sus sistemas y datos con rapidez, el RTO será normalmente más lento en comparación con el uso de la replicación como parte del proceso. Esto se debe a que primero habrá que aprovisionar los sistemas antes de restaurar las aplicaciones y los datos, lo que lleva mucho tiempo.
El software de replicación crea una copia en vivo de sus sistemas críticos para la empresa, que puede incluir la configuración completa del sistema, y sincroniza periódicamente estos datos entre su sistema primario de producción y la copia secundaria de ese sistema. Si se produce un desastre, puede transferir rápidamente su negocio de la copia primaria a la copia secundaria, un proceso conocido como conmutación por error. Esto minimiza el tiempo de inactividad de la empresa (RTO) y la posible pérdida de datos, ya que las sincronizaciones entre los dos sistemas son mucho más frecuentes que las copias de seguridad completas, conocidas como RPO. La conmutación por error y la recuperación del sistema pueden automatizarse para reducir aún más el tiempo de inactividad del sistema y, en muchos casos, puede alcanzarse un RTO cercano a cero, de forma que cualquier interrupción no sea perceptible para los usuarios del sistema. Cristie El software de recuperación puede detectar fallos y proporcionar automatización de failover/failback a través de la configuración del software Cristie Virtual Appliance (VA). Esencialmente, la replicación se centra más en la continuidad de su negocio y en minimizar el impacto de un desastre en su empresa, mientras recupera sus sistemas secundarios a partir de sus copias de seguridad.
Cristie El software CloneManager crea copias sincronizadas y replicadas de los equipos críticos de su empresa para mantener su negocio en funcionamiento con un tiempo de inactividad y un impacto mínimos para su empresa durante un escenario de DR. Las sincronizaciones pueden configurarse según un calendario definido por el usuario para reducir los RPO, o la pérdida de datos entre los dos sistemas, a minutos. CloneManager también incluye funciones como Automated Failover y Failback para automatizar el proceso de conmutación por error y reducir aún más los RTO y el tiempo de inactividad de la empresa. Las pruebas mejoradas permiten probar las copias replicadas fuera del entorno de producción sin que ello afecte al proceso de sincronización, lo que le proporciona una confianza total en su plan de recuperación ante desastres.
La llegada de la tecnología de virtualización y la computación en nube ha proporcionado a las organizaciones una amplia gama de opciones a la hora de seleccionar una plataforma de destino para la replicación de sistemas. Los sistemas físicos ya no deben replicarse en sistemas físicos similares que se ejecuten en una ubicación de DR. En los casos en los que se requiere una informática de alto rendimiento, la replicación de sistemas físicos similares puede ser esencial. Sin embargo, en muchos casos, la replicación de máquinas físicas a objetivos virtuales o en la nube con fines de recuperación ante desastres es ahora una opción muy viable, y para muchas organizaciones se está convirtiendo en una práctica estándar. La tarea de configurar un objetivo de replicación virtual o basado en la nube y luego gestionar los trabajos de replicación para múltiples máquinas puede parecer una tarea desalentadora. Muchos proveedores de servicios de copia de seguridad y replicación en la nube ofrecen herramientas gratuitas de migración y replicación para ayudar a los clientes con el proceso de incorporación de sistemas de replicación a un entorno de nube virtual. A primera vista, puede parecer una facilidad muy valiosa. El inconveniente es que las herramientas proporcionadas suelen estar diseñadas para replicar sistemas únicamente en el entorno de nube específico del proveedor, por lo que, en el sentido de la movilidad de la replicación, muchas de estas herramientas son unidireccionales. Por supuesto, desde la perspectiva de los proveedores, su interés radica en atraer y mantener clientes, lo que tiene el inconveniente potencial de crear un escenario de dependencia del proveedor para el cliente. Para garantizar la máxima protección y libertad de elección del proveedor de la nube, su DRP debe esforzarse por lograr una movilidad de replicación total, lo que significa que su infraestructura de DR debe ser capaz de replicar sistemas vitales en cualquier dirección, desde y hacia destinos físicos, virtuales y en la nube, con total independencia de la elección del proveedor de la nube. Cristie VA proporciona esta capacidad, lo que permite una libertad total para mover sus sistemas de DR entre proveedores y tipos de plataforma.
Probablemente, la mayor ventaja de la replicación de sistemas in situ es la protección de datos. Como los datos se almacenan localmente en sus instalaciones, usted tiene pleno control sobre ellos y su seguridad. Los datos sensibles no tienen por qué salir de la empresa, lo que puede ser una ventaja decisiva, especialmente cuando se trata de cuestiones de cumplimiento y de garantizar la soberanía de los datos. Otra ventaja clave es el rendimiento. Con cualquier solución de replicación externa, el rendimiento de la recuperación se regirá por la conexión a Internet, SD-WAN o MPLS que tenga con su proveedor de colocación o nube, que en algunos casos puede ser muy inferior al de la replicación local. Como los datos se almacenan localmente en sus instalaciones, tiene pleno control sobre ellos y su seguridad. Los datos sensibles no tienen por qué salir de la empresa, lo que puede ser una ventaja decisiva, especialmente cuando se trata de cuestiones de cumplimiento y de garantizar la soberanía de los datos. Otra ventaja clave es el rendimiento. Con cualquier solución de replicación externa, su rendimiento de recuperación se regirá por la conexión a Internet, SD-WAN o MPLS que tenga con su proveedor de colocación o nube, que en algunos casos puede ser muy inferior al rendimiento disponible dentro de su red interna. Además, su red interna debe ser accesible en cualquier momento, garantizando que los sistemas se replican independientemente del estado de su conexión a Internet. Además, si su empresa no depende de Internet o de servicios basados en la nube para las copias de seguridad y la replicación, es posible que no tenga que pagar por una conexión de alta velocidad, lo que reducirá los costes mensuales de Internet. Como se ha comentado anteriormente, los riesgos de la proximidad a su sistema de producción en caso de un desastre local o natural deben tenerse muy en cuenta a la hora de elegir una solución de recuperación ante desastres local.
que se ha construido específicamente para garantizar la fiabilidad del tiempo de actividad de varios clientes. Los centros de datos de colocación alquilan espacio, donde residen jaulas seguras y suites privadas en un entorno informático ideal para mantener los activos informáticos físicos de las empresas. Encontrar el proveedor de colocación adecuado puede ofrecer enormes ventajas en términos de conectividad de red de operador neutro, incorporación a la nube para conectividad híbrida y conectividad multi-nube a través de una sólida infraestructura de red. En la mayoría de los casos, los centros de datos de colocación pueden ofrecer a sus clientes una solución de TI superior a un coste total inferior y con menos desventajas que las soluciones locales, aunque los costes de configuración iniciales suelen ser más elevados. Cada cliente utiliza sistemas propios, lo que conlleva ciertas ventajas e inconvenientes. Al no ser el propietario del centro de datos, es posible que tenga que seguir ciertas normativas aplicadas a su arrendamiento que pueden restringir el acceso en determinados periodos de tiempo. Realizar el mantenimiento de los equipos requerirá un viaje a la ubicación de su centro de datos de colocación, por lo que es importante comprender las normas de acceso y asegurarse de que estos requisitos satisfacen las necesidades de su empresa. En muchos casos, los inquilinos pueden utilizar los servicios de conserjería y los expertos en TI de las instalaciones de colocación para tareas de mantenimiento y operativas, evitando así desplazamientos innecesarios al centro de datos. En general, para las empresas medianas y grandes, las ventajas de la colocación deberían superar los costes iniciales de instalación para ofrecer una buena combinación de rendimiento y asequibilidad. Esto es especialmente cierto cuando el socio que elija puede proporcionar un servicio de atención al cliente de alto nivel para resolver cualquier problema con su implantación.
La computación en nube está muy consolidada, pero muchas empresas siguen teniendo miedo a migrar sus sistemas y datos a este entorno. Entre las preocupaciones más frecuentes figuran la confidencialidad de la información, la calidad de los servicios y el rendimiento que tendrán las aplicaciones empresariales tras la migración. El desarrollo de una infraestructura de TI híbrida puede servir de puente para aliviar algunas de estas preocupaciones con una solución "lo mejor de ambos mundos", que permita a las empresas elegir qué quieren trasladar a la nube pública, qué mantener en las instalaciones, y decidir qué servicios de copia de seguridad y replicación en la nube utilizar y para qué. Además, las empresas pueden incluir una nube privada dentro de esta arquitectura, que es un entorno interno de computación en nube que ofrece toda la escalabilidad de los servicios de nube pública, pero dedicado exclusivamente a la empresa y accesible sólo por ella. Tanto la infraestructura local como la de nube pública y privada pueden funcionar de forma independiente o conectarse según las necesidades. Por ejemplo, se puede optar por replicar una carga de trabajo crítica, con fuertes requisitos de seguridad o cumplimiento a la nube privada, con procesos menos críticos aprovechando los servicios de la nube pública. Esto proporciona a la empresa un control total sobre la infraestructura y la pila de aplicaciones de DR.
Los sistemas operativos que se ejecutan en máquinas físicas están estrechamente vinculados al hardware subyacente a través de controladores específicos para los periféricos utilizados en la placa del sistema. Algunos ejemplos son los controladores de almacenamiento, los adaptadores gráficos y los adaptadores de red. Si una máquina física de destino de replicación no es idéntica al sistema de origen original, la imagen de replicación del sistema puede no arrancar en la máquina de destino debido a la falta de coincidencia de uno o más controladores de nivel de sistema críticos para el arranque. Esta es una situación con la que muchos administradores de sistemas de TI estarán familiarizados y que implica una cierta cantidad de dificultad y tiempo para aprovisionar el sistema de destino en un estado listo para el arranque antes de que se pueda acceder a las aplicaciones y los datos.
Por el contrario, el software Cristie Recovery proporciona una herramienta fácil de usar para recuperar todo el sistema en cualquier plataforma de hardware, virtual o en la nube. Nuestro software crea un archivo de configuración de la máquina que se guarda con la copia de seguridad. Este archivo de configuración contiene toda la información necesaria para preparar la recuperación en cualquier destino comparable. Los sistemas se pueden recuperar como un clon del sistema original de una sola vez, incluida una recuperación puntual. Esto significa que no se pierde tiempo buscando software, ya que la copia de seguridad contiene todo lo necesario. Si va a realizar la recuperación en un hardware diferente, nos encargaremos de inyectar automáticamente los nuevos controladores antes del arranque inicial del sistema de recuperación de destino. Del mismo modo, si realiza la recuperación en un entorno virtual o en la nube, podemos automatizar por completo la creación de la máquina virtual con la misma CPU, RAM y disco disponibles en la máquina física original.
Las máquinas virtuales (VM) suelen referirse a instalaciones independientes de sistemas operativos (SO) que se ejecutan en un único ordenador, asignando a cada SO una parte de los recursos del sistema del ordenador. Por ejemplo, una máquina virtual Linux puede instalarse sobre un ordenador Windows. Múltiples instalaciones de SO pueden coexistir en la misma máquina física al mismo tiempo, siempre y cuando la máquina tenga un hardware lo suficientemente potente. Esto convierte a las máquinas virtuales en una forma cómoda de ampliar los entornos de escritorio y servidor. Otras ventajas de las máquinas virtuales son su aprovisionamiento sencillo y rápido, su alta disponibilidad y su gran escalabilidad. Desde el punto de vista de la DR, son el rápido aprovisionamiento y la escalabilidad los que hacen de las máquinas virtuales un objetivo de replicación tan atractivo. A través de Cristie Virtual Appliance (VA) es posible replicar o recuperar sistemas desde fuentes físicas o en la nube a máquinas virtuales con la opción de escalar los recursos de las máquinas virtuales para igualar el sistema de origen o modificar recursos específicos hacia arriba o hacia abajo durante el aprovisionamiento. Por ejemplo, es posible que desee replicar a una máquina virtual en ejecución con recursos de sistema inferiores a los de la máquina de origen con fines de recuperación ante desastres sobre la base de que puede aceptar un rendimiento ligeramente inferior durante una conmutación por error del sistema para ahorrar costes, ya que se tratará de una situación temporal hasta que las operaciones puedan volver al entorno de producción normal.
Hasta ahora, hemos hablado de objetivos de replicación que se denominan objetivos "en línea", ya que son máquinas en funcionamiento listas para tomar el relevo del sistema primario en caso de fallo del sistema o de desastre. La ventaja de los objetivos de replicación "en línea" es que están listos para ejecutarse y pueden asumir las operaciones muy rápidamente. El inconveniente es que consumen continuamente recursos informáticos físicos o virtuales mientras esperan a que se produzca un incidente. Para superar esta sobrecarga de mantener en funcionamiento máquinas en espera existe una alternativa en forma de archivos de imagen de disco virtual. Las máquinas virtuales pueden capturarse como una imagen completa del mismo modo que una unidad de sistema de una máquina física puede capturarse como una imagen de disco única. El archivo de imagen contiene todo, incluida la configuración del sistema operativo, las aplicaciones y todos los datos. La replicación del sistema puede realizarse en un archivo de imagen de disco virtual almacenado en un entorno de nube privada o pública en lugar de en una máquina en funcionamiento. Esto tiene una ventaja de coste significativa, ya que sólo se requiere el coste de almacenamiento en la nube para mantener estos archivos de imagen en lugar de almacenamiento más recursos informáticos. La desventaja es que son más lentos de poner en línea que una máquina en funcionamiento, pero para muchos escenarios de DR el RTO que proporcionan es suficiente. Las soluciones de replicación de Cristie proporcionan capacidades de replicación en línea y fuera de línea con soporte para todos los estándares comunes de imagen de sistema, incluidos los formatos de archivo .vhdx, .qcow2 y .vmdk a través de Cristie VA.
Un DRP sólido no debe descuidar la importancia de la red corporativa subyacente. Una organización no puede funcionar correctamente sin que los servicios de red estén disponibles para mover datos dentro de la infraestructura. Por lo tanto, no se puede subestimar la importancia de los servicios de red; un DRP sólido también debe incluir la planificación de la recuperación ante desastres de la red y cubrir las formas de reducir el riesgo de fallo de la red. A medida que la infraestructura de TI sigue alejándose de una topología fija centrada en el hardware para acercarse a arquitecturas definidas por software, los perfiles de red pueden formar parte más fácilmente de su conjunto de copias de seguridad habituales para incluir archivos de configuración de red, incluidos los parámetros y ajustes iniciales para configurar los dispositivos de red tras cualquier desastre de la infraestructura.
Una parte clave de cualquier DRP será la lista de prioridades de recuperación de las aplicaciones de procesos empresariales. Adoptando un enfoque escalonado, los planificadores de la recuperación en caso de catástrofe pueden estructurar el proceso de recuperación para reducir el tiempo de inactividad y proteger los sistemas de alta prioridad. Conceptualmente, los objetivos de punto de recuperación (RPO) y de tiempo de recuperación (RTO) calculados durante la fase de análisis del "coste del tiempo de inactividad" pueden servir de buen punto de partida para determinar las prioridades de recuperación de las aplicaciones.
Evidentemente, muchas aplicaciones dependerán de otras, por lo que la lista de prioridades de recuperación contendrá probablemente grupos de aplicaciones que deban recuperarse y ponerse en línea en una secuencia específica para garantizar que las operaciones de los procesos empresariales puedan fluir sin problemas y sin cuellos de botella. Lo más probable es que el primer grupo de sistemas y aplicaciones que haya que restaurar contenga servidores de infraestructura fundamentales, como el controlador de dominio, necesario al principio para responder a las solicitudes de autenticación de seguridad y verificar a los usuarios en cada dominio de una red informática. Este controlador es el guardián que permite el acceso del host a todos los recursos del dominio.
Si dispone de un sólido DRP, estupendo. Pero si está pensando en recuperar sus sistemas manualmente, el proceso puede ser mucho más complejo de lo que cree. Aunque no es imposible recuperar los sistemas manualmente, necesitará conocimientos específicos de gestión de sistemas operativos, aplicaciones, redes y almacenamiento, así como mucho tiempo. Normalmente, la reconstrucción manual completa de un servidor con aplicaciones puede llevar entre dos y ocho horas, además del tiempo necesario para restaurar los datos. Además, las recuperaciones manuales no suelen estar planificadas, lo que significa que se trabaja a contrarreloj en una situación que puede ser muy estresante. Veamos un proceso de restauración manual paso a paso.
Una recuperación manual es una operación compleja y lenta; compárela con los 10 a 15 minutos necesarios para una recuperación con un software dedicado de Bare Machine Recovery que proporciona automatización y orquestación de la recuperación y, con suerte, estará de acuerdo en que la respuesta es un rotundo "sí".
"Según la revista Storage Magazine, más del 34% de las empresas no comprueban sus copias de seguridad y, de las que las comprueban, el 77% no consiguen restaurarlas. Según Microsoft, el 42% de los intentos de recuperación de copias de seguridad en cinta del año pasado fracasaron. Un estudio realizado por la National Archives & Records Administration de Washington concluyó que "el 93% de las empresas que perdieron su centro de datos durante 10 días o más debido a un desastre se declararon en quiebra en el plazo de un año tras el desastre". Sin una comprobación adecuada de su conjunto de copias de seguridad, los resultados pueden ser devastadores para su organización en caso de que se produzca un desastre.
Probar regularmente la recuperación de las copias de seguridad es crucial por tres razones: en primer lugar, para identificar cualquier problema con antelación; en segundo lugar, para resolverlo y, por último, para generar confianza en las copias de seguridad, de modo que, cuando las necesite de verdad, pueda recuperarlas rápida y eficazmente para cumplir sus RPO y RTO. El peor momento para descubrir un problema con las copias de seguridad o el proceso de recuperación es cuando se está en medio de una catástrofe real y se depende de ellas para volver a poner en marcha la empresa. Cualquier problema que surja durante un desastre no sólo puede retrasar su recuperación, sino que puede hacer que sus sistemas sean totalmente irrecuperables. Desgraciadamente, probar manualmente sus servidores con regularidad es una tarea que lleva mucho tiempo, especialmente si desea realizar pruebas en todo su centro de datos. Por ello, Cristie Software incluye la funcionalidad de pruebas de recuperación automatizadas para todos nuestros clientes de recuperación de sistemas como parte de sus licencias.
Si está pensando en realizar pruebas manuales de recuperación, le decimos que se lo piense detenidamente. A menudo, las pruebas manuales implican que sólo puede probar eficazmente sus sistemas más críticos. ¿Utiliza software de terceros? Hemos hablado con muchos clientes que han utilizado software de terceros para realizar sus pruebas. A veces, sólo se prueba una muestra de los sistemas y, a menudo, esa muestra puede ser tan baja como el 10-20%. Esta muestra se utiliza para construir una imagen generalizada de la salud de su copia de seguridad, que no refleja necesariamente la realidad. Cuando se utiliza Cristie Software para las pruebas de recuperación, el proceso está automatizado y programado. Esto ha permitido a nuestros clientes probar la totalidad de sus servidores y confiar en que pueden recuperar cualquiera de sus sistemas tras un desastre.
La orquestación de DR puede ayudar a la recuperación ordenada de su entorno de servidores durante una interrupción, asegurándose de que sus servidores, aplicaciones y datos críticos vuelvan a estar en línea sin incidentes y de forma automatizada. Cristie La orquestación de DR va un paso más allá de las recuperaciones automatizadas, ya que le ofrece la posibilidad de planificar y configurar de antemano todas las etapas necesarias para que sus sistemas críticos para la empresa vuelvan a funcionar después de un desastre de servidor. La orquestación de DR se incluye como una de las funciones de valor añadido de Cristie Virtual Appliance (VA). Tanto el VA como la orquestación de DR son de uso gratuito para todos nuestros clientes de recuperación y replicación de sistemas.
Cada trabajo de orquestación se ejecuta a través de una serie de etapas; y dentro de cada etapa podemos ejecutar tantas tareas diferentes como queramos en paralelo. Por ejemplo, podemos ejecutar tareas de replicación o recuperación (con recuperaciones directamente desde su servidor de copia de seguridad IBM Spectrum Protect, Dell Networker/Avamar o Cohesity), reinicios, scripts y tareas de generación de informes que le ofrecen un resumen detallado del trabajo de orquestación. Incluso podemos hacer cosas como añadir tareas manuales, que detendrán la automatización mientras se realiza esa tarea (como cargar una unidad de cinta), antes de continuar la orquestación una vez que se haya completado la tarea.
Todo ello está diseñado para utilizar la automatización para ahorrarle tiempo cuando más importa, minimizando la interacción humana y la posibilidad de error humano en lo que históricamente ha sido un proceso muy manual. La orquestación de la recuperación ante desastres también puede utilizarse para mejorar su régimen de pruebas de recuperación ante desastres, ya que no sólo puede probar las recuperaciones, sino también los procesos circundantes necesarios para que su empresa vuelva a funcionar. Al poder probar los procesos circundantes, como el reinicio del sistema, la integración entre aplicaciones o cualquier script posterior al arranque, podrá detectar y solucionar cualquier problema de antemano en todo el proceso antes de que lo necesite en un escenario de recuperación ante desastres real. Esto significa que, en caso de que tenga que realizar una recuperación real, puede confiar en su capacidad para recuperar los sistemas críticos de su empresa de forma rápida y sencilla.
Al igual que con nuestra función de pruebas de recuperación, los trabajos de orquestación de DR se pueden configurar y programar con meses de antelación, con informes completos por correo electrónico sobre los éxitos y los fracasos que se pueden utilizar para auditorías, cumplimiento, normativas del sector o, si es un proveedor de servicios, como parte de los informes de SLA a su cliente.
En el proceso de pruebas de recuperación de desastres se presentan muchas situaciones de fallo que, sin duda, son mucho más cómodas de tratar durante la fase de pruebas que bajo la presión de una emergencia real. Durante las pruebas se producen una serie de fallos de origen técnico y humano, entre los que se incluyen los que con más frecuencia se registran en nuestro software o los que experimentan nuestros clientes.
Además de fomentar la confianza en las copias de seguridad a nivel interno, las pruebas de recuperación de Cristietambién pueden ayudarle a cumplir las medidas de auditoría y cumplimiento normativo gubernamentales o sectoriales que son habituales en sectores como la sanidad y los servicios financieros (por ejemplo, las normativas HIPPA y FSA). Todas nuestras pruebas automatizadas de recuperación pueden ir seguidas de informes detallados por correo electrónico sobre los éxitos, los fracasos, el tiempo que se tarda en restaurar y los problemas encontrados para ofrecerle un registro completo de los resultados de sus pruebas. Además de estos informes, también podemos realizar un seguimiento de las pruebas con configuraciones adicionales, como eliminar las pruebas satisfactorias para liberar espacio en disco y dejar las recuperaciones fallidas en su lugar mientras investiga por qué falló la recuperación.
Enlaces a herramientas de planificación y sitios de información útiles
Gobierno de los Estados Unidos. Lanzada en febrero de 2003, Ready es una campaña nacional de servicio público diseñada para educar y capacitar al pueblo estadounidense para prepararse, responder y mitigar las emergencias, incluidas las catástrofes naturales y las provocadas por el hombre. El objetivo de la campaña es promover la preparación a través de la participación pública.
Plan informático de recuperación en caso de catástrofe https://www.ready.gov/it-disaster-recovery-plan
Universidad de Indiana - Recursos para profesionales de TI Planificación de la recuperación en caso de catástrofe https://informationsecurity.iu.edu/resources-professionals/disaster-recovery-planning.html
Ejemplo IBM: Plan de recuperación en caso de catástrofe https://www.ibm.com/docs/en/i/7.1?topic=system-example-disaster-recovery-plan
Calculadora de costes de inactividad de EATON https://powerquality.eaton.com/Products-services/Help-Me-Choose/DowntimeCostCalculator/Default.asp
Está claro que la planificación de la recuperación ante desastres y el propio proceso de recuperación ante desastres son tareas de enorme importancia y, como es lógico, desalentadoras para muchas organizaciones. El coste de aprovisionar sistemas de copia de seguridad y redundancia no es insignificante, sin embargo, para muchos este coste se convierte en minúsculo cuando se compara con el coste del tiempo de inactividad, o incluso peor, las demandas de largo alcance de un ataque de ransomware. A diferencia de la mayoría de las decisiones en el diseño de procesos empresariales, la planificación de la recuperación ante desastres implica muchas concesiones basadas en el análisis de riesgos y el nivel de servicio que requieren sus clientes, proveedores y empleados. Esperamos que esta guía haya ilustrado que tanto la copia de seguridad como la replicación tienen un papel importante que desempeñar en cualquier estrategia sólida de recuperación ante desastres y, en muchos casos, es poco probable que se utilice alguna de ellas de forma aislada. Gracias a los avances en la computación en nube, las organizaciones disponen ahora de una amplia gama de opciones de objetivos de copia de seguridad y replicación en términos de ubicación y tipo: físicos, virtuales y en la nube. La movilidad de la copia de seguridad y la replicación también es una característica clave que debe incluirse en cualquier DRP para evitar la dependencia de un solo proveedor o la posibilidad de puntos únicos de fallo en el plan de redundancia. Para obtener más información sobre la recuperación, replicación y migración de sistemas, hable con el equipo de Cristie Software, que siempre está a su disposición para responder a cualquier pregunta.
1. [en línea] consultado el 9 de febrero de 2022, https://www.ccn.com/facebooks-blackout-90-million-lost-revenue/
2. [en línea] consultado el 9 de febrero de 2022, https://money.cnn.com/2016/09/07/technology/delta-computer-outage-cost
3. [en línea] consultado el 9 de febrero de 2022, https://blogs.gartner.com/andrew-lerner/2014/07/16/the-cost-of-downtime/
4. [en línea] consultado el 9 de febrero de 2022, https://www.usenix.org/conference/fast16/technical-sessions/presentation/schroeder
5. [en línea] consultado el 9 de febrero de 2022, https://purplesec.us/resources/cyber-security-statistics/
6. [en línea] consultado el 9 de febrero de 2022, https://en.wikipedia.org/wiki/2021_Texas_power_crisis