


Bestimmung der Kosten und des Standorts der technischen Schulden anhand von Geschwindigkeitsmessungen in einer DevOps-Organisation.

Technische Schulden werden (über Wikipedia) definiert als:
Die impliziten Kosten zusätzlicher Nacharbeit, die dadurch entstehen, dass man sich jetzt für eine einfache Lösung entscheidet, anstatt einen besseren Ansatz zu wählen, der länger dauern würde.
Viele gehen davon aus, dass diese Schuld ausschließlich im Code zu finden ist, und messen die zyklomatische Komplexität, die Testabdeckung und/oder verwenden einen Linter, um festzustellen, wie viel Schuld vorhanden ist und wo sie sich befindet. Diese Maßnahmen funktionieren gut - aber sie zeigen nicht auf, welche Art von Schuld (Komplexität, fehlende Tests, schlechte Dokumentation) die größten Probleme verursacht oder wo man am besten ansetzen sollte. Sie messen auch nicht die Arten von Schulden, die schwieriger zu erkennen sind, zum Beispiel:
- Duplizierung von Merkmalen
- Der gesamte Baustein wird vervielfältigt, aber anders geschrieben, vielleicht in einer anderen Sprache
- Kein Entwurf für Fehlersuche
- Die Fehlersuche ist schwierig, wenn ein Fehler in unmittelbarer Nähe (beim Kunden, in der QA-Abteilung) auftritt, weil die Protokollierung, die Fehlerberichterstattung oder die Freigabe/Debug-Variante unzureichend sind.
- Langsame Testsuite
- Die Ausführung der Testsuite nimmt viel Zeit in Anspruch, was zu einem höheren Durchsatz führt.
- ...
Diese ziehen möglicherweise die Standarddefinition von technischer Schuld ein wenig in die Länge, daher verwenden wir bei Cristie die folgende:
Die Kosten für zusätzliche Arbeit, die dadurch entstehen, dass man sich jetzt für eine einfache Lösung entscheidet, anstatt einen besseren Ansatz zu wählen, der länger dauern würde.
Damit haben wir eine Möglichkeit, dies herauszufinden:
- Wenn wir davon ausgehen, dass es besser ist, sich häufiger zu engagieren
(...und wir sagen, dass es so ist, und ermutigen die Leute, es zu tun...) - dann ist der einzige Grund, warum Sie sich nicht häufiger engagieren, der, dass Sie es nicht können
- und den Grund dafür, dass Sie das nicht können, definieren wir als unsere technische Schuld, weil
- wenn wir ein Re-Factoring, eine Architektur oder eine andere Verbesserung vornehmen würden, könnten Sie das tun.
Wir können technische Schulden also wie folgt messen:
Die Zeit, die für Commits über α Standardabweichungen aufgewendet wird, die eine Datei enthalten, die α Standardabweichungen vom Üblichen entfernt ist.
Das heißt, die Menge an zusätzlicher Zeit für Commits, die Dateien enthalten, die routinemäßig in Commits erscheinen, die länger dauern.
Unsere Commit-Historie herausfinden
Wir haben ein Python-Skript geschrieben, das Subversion- und Git-Protokolle verarbeitet und erzeugt:
- Der Autor der Übergabe
- Die Geschäftszeit seit dem letzten Commit des Autors in irgendeinem Repo
- Die Dateien in dieser Übertragung
Anschließend haben wir diese Übertragungen für jeden Autor normalisiert und dieses Diagramm erstellt:
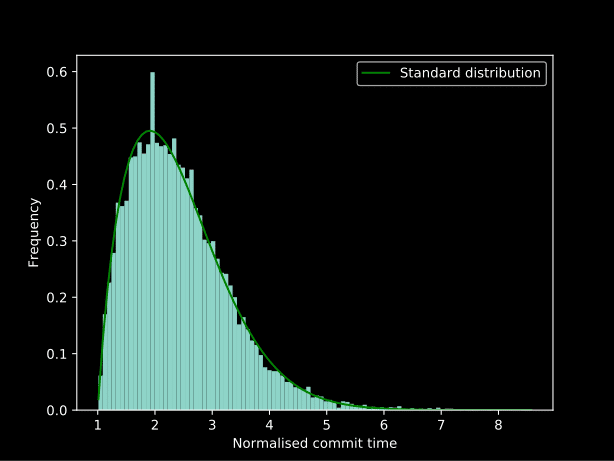
Einige Versuche und Irrtümer (es gibt definitiv einen besseren Weg, es zu tun... aber das statistische Wissen wurde während des Experiments gelernt) festgestellt, dass die Anwendung lambda x: np.log(x) ** 2 als zwei gleichzeitige Box-Cox-Transformationen ergibt eine sehr und die umgekehrte Anwendung dieser Methode ergibt die am besten passende Linie im obigen Diagramm:
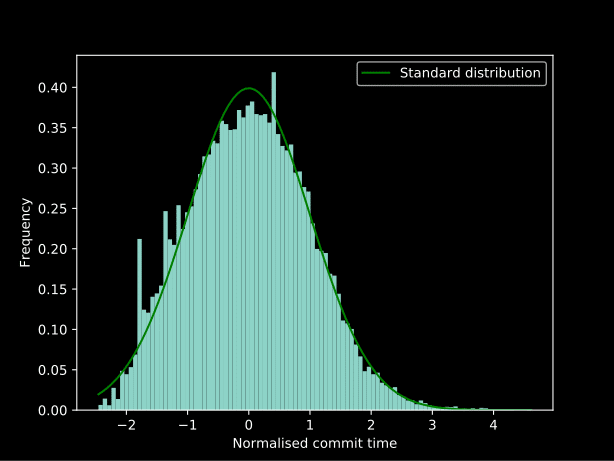
Technische Schulden
Wir können nun die technische Schuld ermitteln, indem wir den z-Score (ein Maß dafür, wie "normal" eine Population ist, die normal sein sollte) für jede Datei berechnen:
[code lang=”python”]
def zscore(commits):
"Z-Score per-file for all files in commits"
perpath = collections.defaultdict(list)
for commit in commits:
for path in commit.paths:
perpath[path].append(commit.interval)
return {path : sum(perpath[path]) / math.sqrt(len(perpath[path]))}
[/code]
Das heißt, wir können die Zinsen berechnen, die wir für technische Schulden zahlen:
[code lang="python"]
def debt(commits, deviation=1):
"Gesamtschulden für diese Reihe von Commits"
scores = zscore(commits)
debt = 0
for commit in commits:
for path in commits.paths:
if scores[path] > deviation:
debt += commit.duration -
inverse(0) -
inverse(deviation)
return debt * 100.0 / sum(c.duration for c in commits)
[/code]
Durch die Verwendung eines gleitenden Fensters können wir ein Diagramm der technischen Schulden über die Zeit erstellen und die Dateien finden, die dazu beitragen. Die folgende Abbildung zeigt die Anzahl der Commits für Dateien mit hohem Interesse im Vergleich zu normalen Dateien:
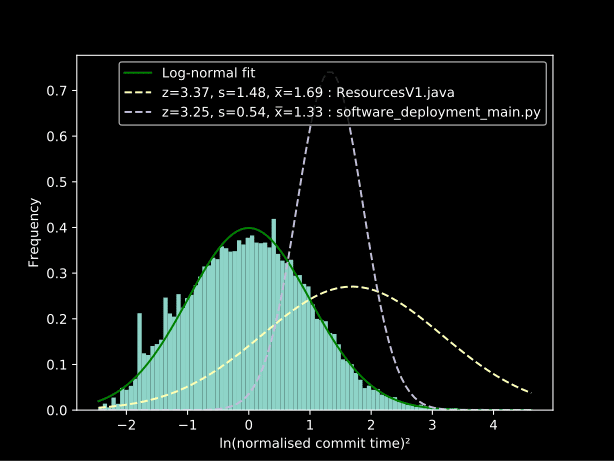
Ergebnisse
Die technischen Schulden aus dem Jahr 2018 liegen bei rund 20 %:
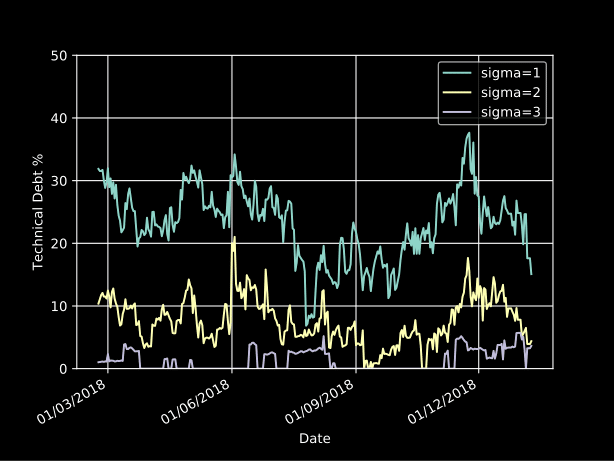
Noch wichtiger ist, dass wir dadurch eine Liste von Dateien erhalten, an denen wir arbeiten müssen (zum Schutz der Unschuldigen editiert):
| Z-Score | % Zusagen | Multiplikator | Dateiname | |
|---|---|---|---|---|
| 3.18 | 1.66 % | 2.44x | Dockerdatei der Appliance | |
| 0.82 | 4.76 % | 2.14x | Lizenzierungscode für neues Produkt | |
| 2.94 | 0.98 % | 2.15x | Entfernte Python-REST-API |
In den oben genannten Fällen waren wir uns im Team einig, dass es sich um problematische Bereiche handelte. Unsere Diagnose lautete in der Reihenfolge:
- Dockerdatei der Appliance
- Die Größe der Appliance war zu groß, so dass das Herunterladen der benötigten Pakete von Nexus über das Netzwerk zu einer großen Verzögerung beim Roundtrip führte.
Um dem entgegenzuwirken, haben wir die Größe der Appliance deutlich reduziert. - Lizenzierungscode für neues Produkt
- Dieser Code wurde eingekauft und hatte eine Reihe von Problemen:
- Nicht übereinstimmende Kompilierung von 32/64 Bit und Big/Little-Endian-Architekturen
- Duplizierte, aber ähnlich benannte Funktionen, z.B.
CheckLicencegegencheck_licence - Irreführende Namen (
dsUint32_tist eigentlich nur einint...)
Wir haben diesen Code umfangreich überarbeitet und Tests hinzugefügt, um dieses Problem zu beheben.
- Entfernte Python-REST-API
- Dies hatte eine hohe zyklische Komplexität und eine geringe Dokumentation zur Folge, vor allem aber eine hohe Durchlaufzeit der Integrationstests.
Dies wurde verbessert, indem einige der Phasen des Integrationstests für jeden Test entfernt wurden.
Argumente gegen diesen Ansatz
Was ist mit Dingen, die nicht in die Versionskontrolle gehören?
Zunächst einmal sollte alles unter Versionskontrolle stehen! Ganz einfach. Natürlich gibt es immer Aktionen, die nicht in der Versionskontrolle sind - aber diese sind entweder unabhängig von der aktuellen Übergabe (und beeinflussen die Daten nicht, wenn sie in großen Mengen gemacht werden) oder sie beeinflussen die aktuelle Übergabe - in diesem Fall sind sie technische Schulden.
Was ist, wenn manche Menschen mehr Sorgfalt walten lassen als andere?
Wir normalisieren auf der Basis der einzelnen Autoren, um zu versuchen, unsere Daten auf den Code und den Prozess und nicht auf die Person zu beziehen.
Die Zinsen werden nur gezahlt, wenn der Code gerade aktiv ist, so dass ein Rückgang der Zinsen nur bedeuten kann, dass der derzeit aktive Code besser ist.
Das ist sehr wahr... und definitiv ein Problem. Inaktiver Code mit hohen technischen Schulden stellt ein Risiko dar, behindert aber nicht wirklich die Entwicklung... noch nicht. Hier können sekundäre Metriken (Komplexität, Abdeckung und Linting) helfen - insbesondere, wenn eine Verbindung zum empirischen Maß der Verschuldung gefunden werden kann. ...beobachten Sie diesen Bereich.
