


There is a saying from “The Tao of Backup” written in the days of NT4 that runs:
To believe in one’s backups is one thing. To have to use them is another.
This is frequently shortened to simply “Test your recoveries!” or:
If you haven’t tested your recoveries, you do not have backups.
This is all well and good, but in heterogeneous computing environments things can get a little bit tough. You can use SureBackup to test your Windows VMs, but what about your Windows XP box controlling your CNC? For that matter, what about the Solaris 9 box that runs your oscilloscope?
Things can get even more tricky… what if your Solaris 9 box uses Kerberos authentication and requires the controller to be restored first?
Many modern tools promise a push-button-to-test-my-backups… which is great, but they’ll only work if all your systems fit their criteria. One physical legacy system in the mix… and suddenly you’re unprotected – and that is the system that is most likely to break!
The Strategy
The first thing to do is to figure out how to restore the systems and data manually and document that process.
An example Solaris 9 recovery plan might be:
- Recover flar image from disk using installer
- Recover data using tar from tape
- Boot
- Run test commands
An example VM recovery on the other hand might simply be:
- Select the recover VM plan from ${insert backup product here}
Unfortunately, if the Solaris 9 machine relied on this (e.g. it provides Kerberos authentication) you need to combine them. They need to be on the same VLAN, they need to boot in a specific order and they need to be tested in order.
An example plan
An example plan for a Solaris 9 machine connected to an A/D on Kerberos could be:
| Solaris Machine | A/D Controller |
|---|---|
| Recover flar image from disk | Recovery VM image |
| Recover data using tar from tape | Boot VM image |
| WAIT → | Test A/D controller |
| Boot Solaris Machine | |
| Test Solaris Machine |
Even in a simple case we have a dependency on a test prior to boot. In a more complicated scenario we can have multiple dependencies. For example, say we have a web interface to the legacy Solaris application run on a LAMP stack:
| LAMP Stack | Solaris Machine | A/D Controller |
|---|---|---|
| Recover VM image | Recover flar image from disk | Recover VM image |
| Recover data using tar from tape | Boot VM image | |
| WAIT → | Test A/D controller | |
| Boot Solaris Machine | ||
| WAIT → | Test Solaris Application | |
| Boot Linux Machine | ||
| Test Web UI |
This will work, but there are more problems here:
- What if booting the Solaris machine takes a long time? Wouldn’t it be nice to start it earlier?
- If the Linux recovery fails at the OS level, we could find that out without the other machines. Same for the Solaris Machine – and that recovery might take a long time if the data is coming back from tape…
| LAMP Stack | Solaris Machine | A/D Controller |
|---|---|---|
| Recover VM image | Recover flar image from disk | Recover VM image |
| Disable web service | Disable application | Boot VM image |
| Boot | Boot | |
| Test OS is operational | Test OS is operational | |
| Recover data using tar from tape | ||
| WAIT → | Test A/D controller | |
| WAIT → | Test Solaris Application | |
| Enable web service | ||
| Test Web UI |
So now we have a plan that will fail as early as possible in the event of an operating system error. This can probably be improved still further though; it might be possible to restore a subset of data to perform a fast application test prior to the slow one, it may be possible to (partially) test the Web UI in isolation etc…
Requirements for Automation
A plan like this requires:
- An orchestration platform with free control of provisioning
- Post-recovery scripting prior to reboot to control the booting OS
- APIs to boot recovered machines for a variety of platforms
- A testing platform with an API
Tools for the Job
An orchestration platform
We’re using Jenkins to manage this particular operation as, in our case, Jenkins is also managing the construction of the recovery software. Jenkins may be easily scripted and has plugins for the major VM providers so would serve as a good basis for many organisations.
Recovery and post-recovery scripting
Of course we’ll recommend Cristie BMR that supports Solaris, Linux and Windows (and AIX) and offers post-recovery scripting. It is possible to do this piecemeal with different tools though: JumpStart can be used with Solaris and FLAR very effectively, although there is a fair bit of effort involved. Post-recovery scripting a VM recovery can be tricky but booting into a Linux live-environment after recovering the VM would work well.
APIs to control boot
All hypervisors have APIs to boot VMs… but what about physical kit? A solution we use is to connect via a serial port and use pyserial to orchestrate the machine.
A testing platform
We’re using Jenkins again for this, but running scripts using bats. This is a nice way of very quickly writing some simple checks that can be displayed in Jenkins. However, a more complete solution would be to use serverspec or similar.
Example
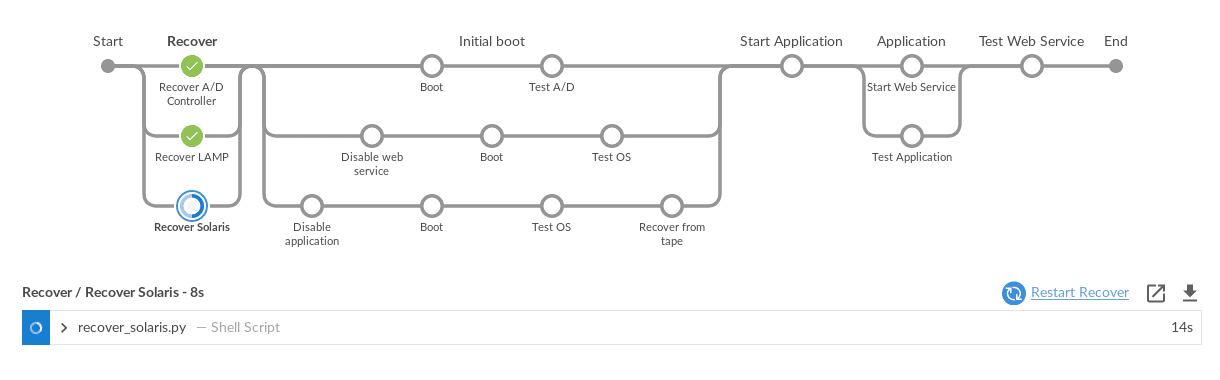
The Jenkins “blue-ocean” plugin provides a very clear view of the progress of a test: At this stage we have begun using Cristie CBMR to restore a Solaris 9 system to physical hardware. Once complete a short script will disable the required application on boot and set up the network parameters to be used on boot.
The python script that performs this will:
- Boot the machine using network boot from a PXE server which contains the CBMR image
- Begin the restore from the OS backup
Once complete the machine can be accessed via the network instead of the serial console and the standard Jenkins scripting can be used.
Completion
The pipeline will only run each stage in order, so stages are used to separate concurrent actions.
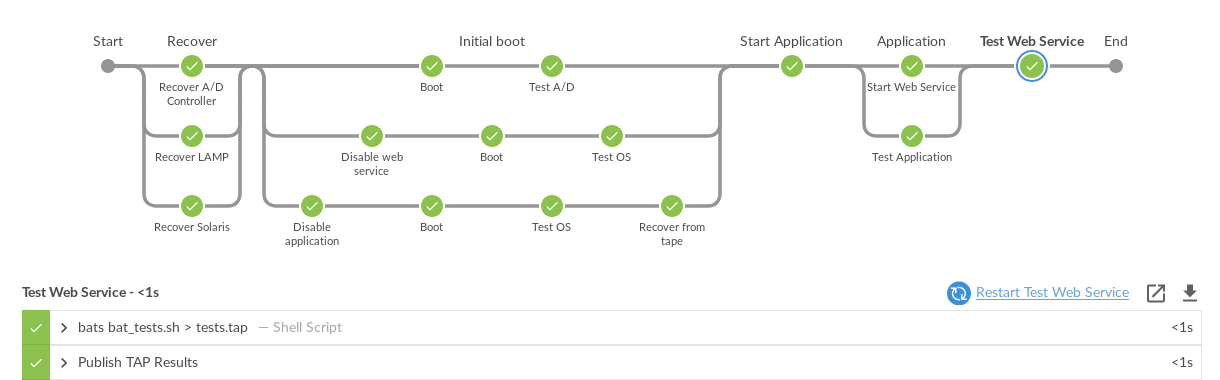
It is clear from the above plan that the A/D must be tested before the application can be started, that the application must be started before the web service is started and that the web service can only be tested after it is started. It is possible to use the “Lockable resource plugin” to create finer grained control but this is harder and comes with greater risk.
At the end of the recovery test we get the following (significantly shortened) output and a log file:

Summary
It is possible to use modern CI tools to test disaster recovery of older operating systems provided that the tools support:
- An API to control the environment that will be booted
- An API to control when the environment will be booted
- Orchestration hooks to provision environments for recovery
Many backup systems do not provide these capabilities. In particular, few tools provide hooks that allow you to provision a recovery environment.
TBMR
TBMR was used for the restore of the operating systems. It has been designed to work with Windows, Linux, Solaris and AIX:

